 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Text Embedding for Personalized Content-based Recommendation
Paper and Code
Jun 23, 2017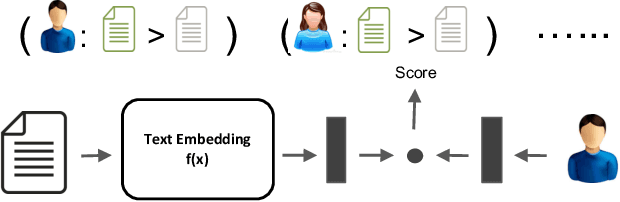
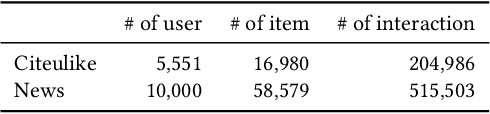


Learning a good representation of text is key to many recommendation applications. Examples include news recommendation where texts to be recommended are constantly published everyday. However, most existing recommendation techniques, such as matrix factorization based methods, mainly rely on interaction histories to learn representations of items. While latent factors of items can be learned effectively from user interaction data, in many cases, such data is not available, especially for newly emerged items. In this work, we aim to address the problem of personalized recommendation for completely new items with text information available. We cast the problem as a personalized text ranking problem and propose a general framework that combines text embedding with personalized recommendation. Users and textual content are embedded into latent feature space. The text embedding function can be learned end-to-end by predicting user interactions with items. To alleviate sparsity in interaction data, and leverage large amount of text data with little or no user interactions, we further propose a joint text embedding model that incorporates unsupervised text embedding with a combination module. Experimental results show that our model can significantly improve the effectiveness of recommendation systems on real-world datasets.