 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unbiased Data Collection and Content Exploitation/Exploration Strategy for Personalization
Paper and Code
Apr 12, 2016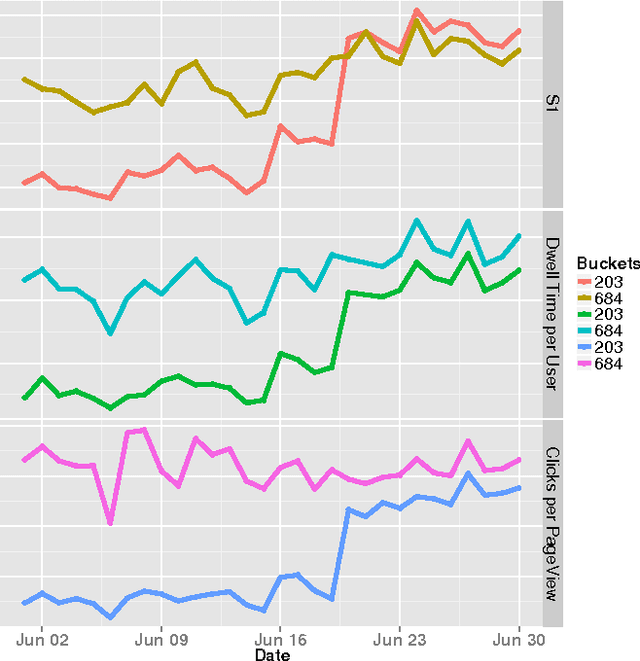
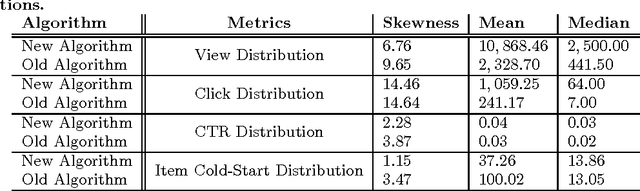
One of missions for personalization systems and recommender systems is to show content items according to users' personal interests. In order to achieve such goal, these systems are learning user interests over time and trying to present content items tailoring to user profiles. Recommending items according to users' preferences has been investigated extensively in the past few years, mainly thanks for the popularity of Netflix competition. In a real setting, users may be attracted by a subset of those items and interact with them, only leaving partial feedbacks to the system to learn in the next cycle, which leads to significant biases into systems and hence results in a situation where user engagement metrics cannot be improved over time. The problem is not just for one component of the system. The data collected from users is usually used in many different tasks, including learning ranking functions, building user profiles and constructing content classifiers. Once the data is biased, all these downstream use cases would be impacted as well. Therefore, it would be beneficial to gather unbiased data through user interactions. Traditionally, unbiased data collection is done through showing items uniformly sampling from the content pool. However, this simple scheme is not feasible as it risks user engagement metrics and it takes long time to gather user feedbacks. In this paper, we introduce a user-friendly unbiased data collection framework, by utilizing methods developed in the exploitation and exploration literature. We discuss how the framework is different from normal multi-armed bandit problems and why such method is needed. We layout a novel Thompson sampling for Bernoulli ranked-list to effectively balance user experiences and data collection. The proposed method is validated from a real bucket test and we show strong results comparing to old algorithms