 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
Oct 20, 2023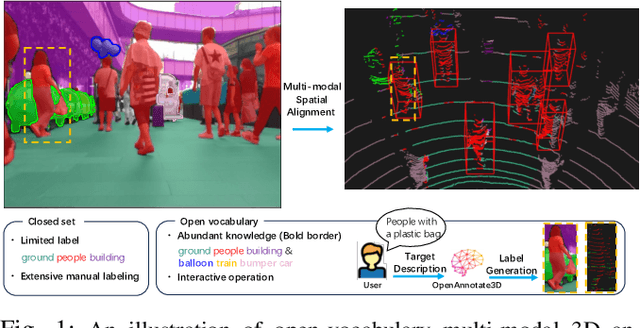
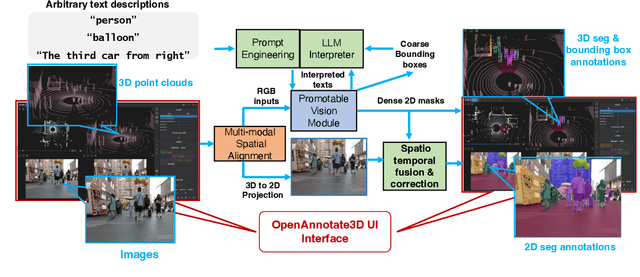
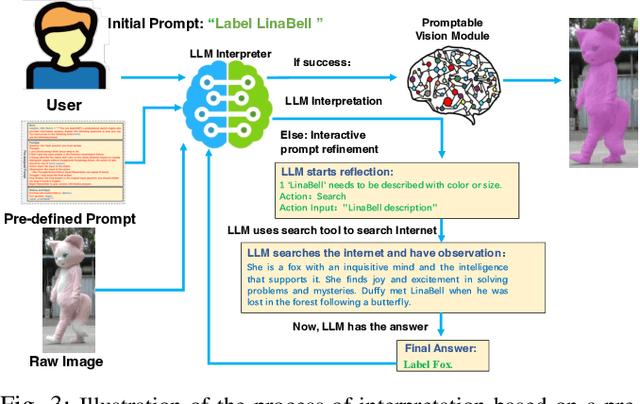
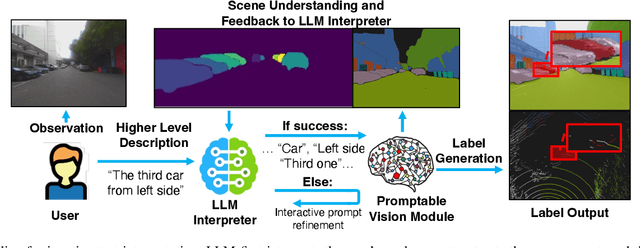
In the era of big data and large models, automatic annotating functions for multi-modal data are of great significance for real-world AI-driven applications, such as autonomous driving and embodied AI. Unlike traditional closed-set annotation, open-vocabulary annotation is essential to achieve human-level cognition capability. However, there are few open-vocabulary auto-labeling systems for multi-modal 3D data. In this paper, we introduce OpenAnnotate3D, an open-source open-vocabulary auto-labeling system that can automatically generate 2D masks, 3D masks, and 3D bounding box annotations for vision and point cloud data. Our system integrates the chain-of-thought capabilities of Large Language Models (LLMs) and the cross-modality capabilities of vision-language models (VLMs). To the best of our knowledge, OpenAnnotate3D is one of the pioneering works for open-vocabulary multi-modal 3D auto-labeling. We conduct comprehensive evaluations on both public and in-house real-world datasets, which demonstrate that the system significantly improves annotation efficiency compared to manual annotation while providing accurate open-vocabulary auto-annotating results.
Understanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Jun 19, 2023
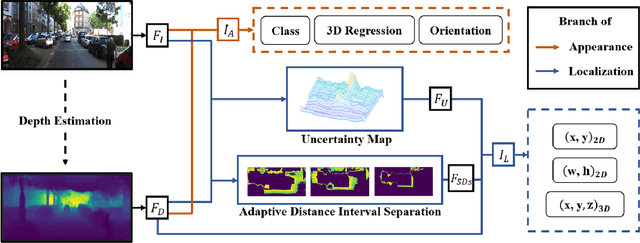
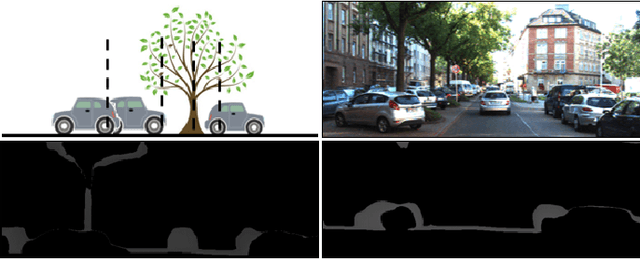
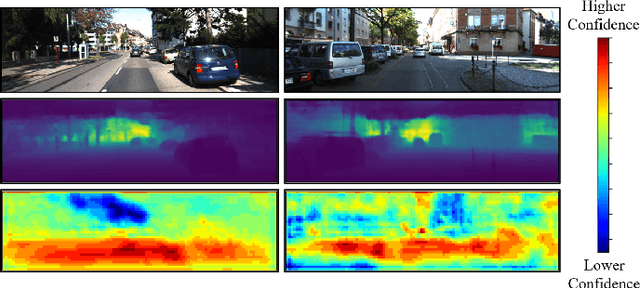
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.
The Devil is in the Task: Exploiting Reciprocal Appearance-Localization Features for Monocular 3D Object Detection
Dec 28, 2021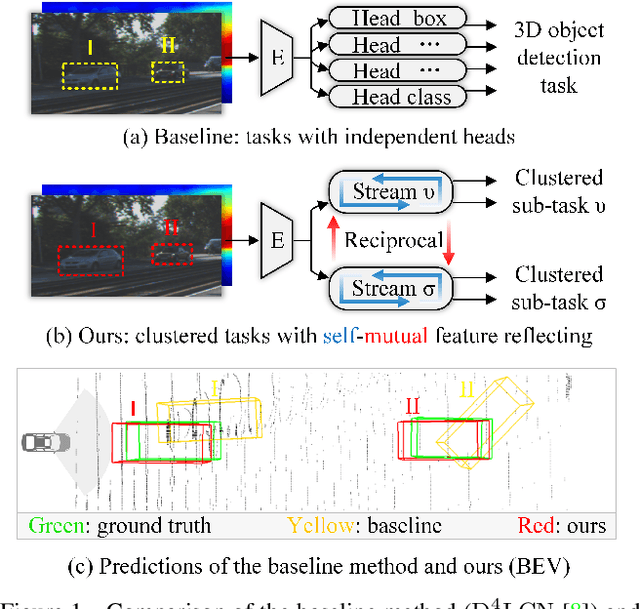
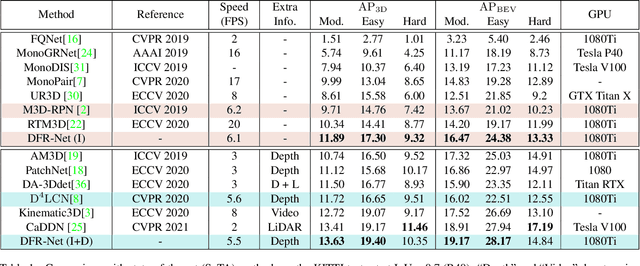
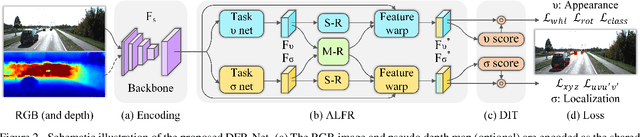
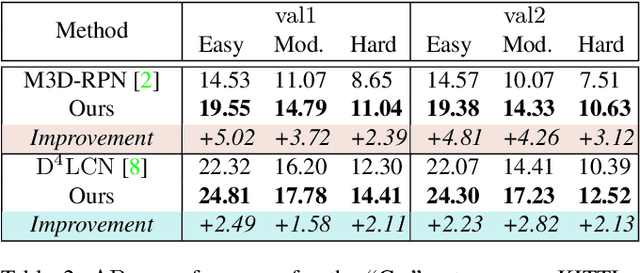
Low-cost monocular 3D object detection plays a fundamental role in autonomous driving, whereas its accuracy is still far from satisfactory. In this paper, we dig into the 3D object detection task and reformulate it as the sub-tasks of object localization and appearance perception, which benefits to a deep excavation of reciprocal information underlying the entire task. We introduce a Dynamic Feature Reflecting Network, named DFR-Net, which contains two novel standalone modules: (i) the Appearance-Localization Feature Reflecting module (ALFR) that first separates taskspecific features and then self-mutually reflects the reciprocal features; (ii) the Dynamic Intra-Trading module (DIT) that adaptively realigns the training processes of various sub-tasks via a self-learning manner. Extensive experiments on the challenging KITTI dataset demonstrate the effectiveness and generalization of DFR-Net. We rank 1st among all the monocular 3D object detectors in the KITTI test set (till March 16th, 2021). The proposed method is also easy to be plug-and-play in many cutting-edge 3D detection frameworks at negligible cost to boost performance. The code will be made publicly available.