 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
Paper and Code
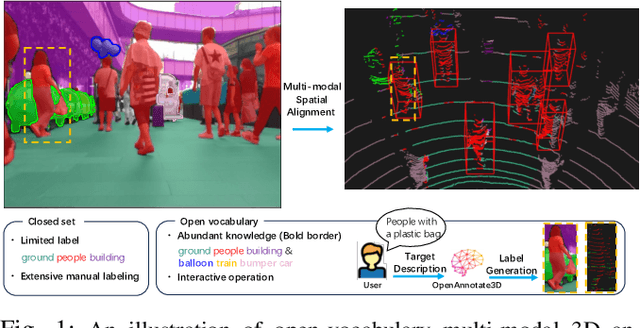
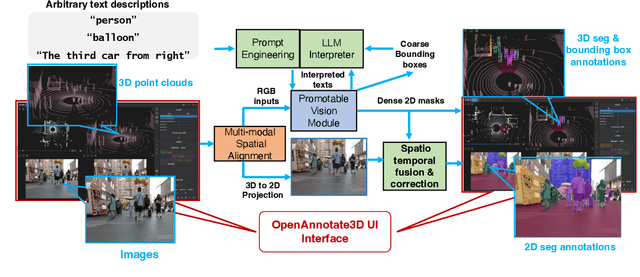
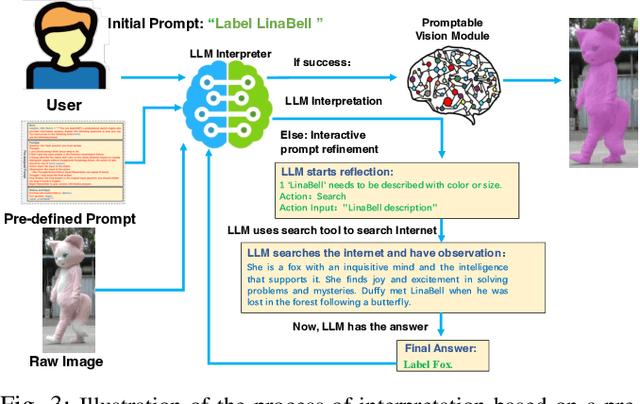
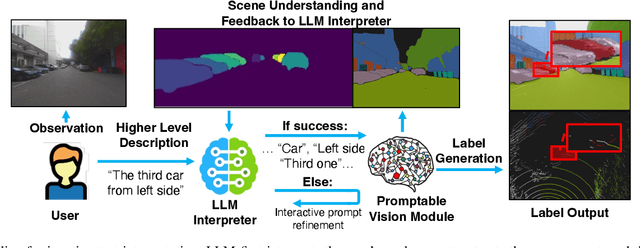
In the era of big data and large models, automatic annotating functions for multi-modal data are of great significance for real-world AI-driven applications, such as autonomous driving and embodied AI. Unlike traditional closed-set annotation, open-vocabulary annotation is essential to achieve human-level cognition capability. However, there are few open-vocabulary auto-labeling systems for multi-modal 3D data. In this paper, we introduce OpenAnnotate3D, an open-source open-vocabulary auto-labeling system that can automatically generate 2D masks, 3D masks, and 3D bounding box annotations for vision and point cloud data. Our system integrates the chain-of-thought capabilities of Large Language Models (LLMs) and the cross-modality capabilities of vision-language models (VLMs). To the best of our knowledge, OpenAnnotate3D is one of the pioneering works for open-vocabulary multi-modal 3D auto-labeling. We conduct comprehensive evaluations on both public and in-house real-world datasets, which demonstrate that the system significantly improves annotation efficiency compared to manual annotation while providing accurate open-vocabulary auto-annotating results.