 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Hungarian: Match-Free Supervision for End-to-End Object Detection
Mar 09, 2026Recent DEtection TRansformer (DETR) based frameworks have achieved remarkable success in end-to-end object detection. However, the reliance on the Hungarian algorithm for bipartite matching between queries and ground truths introduces computational overhead and complicates the training dynamics. In this paper, we propose a novel matching-free training scheme for DETR-based detectors that eliminates the need for explicit heuristic matching. At the core of our approach is a dedicated Cross-Attention-based Query Selection (CAQS) module. Instead of discrete assignment, we utilize encoded ground-truth information to probe the decoder queries through a cross-attention mechanism. By minimizing the weighted error between the queried results and the ground truths, the model autonomously learns the implicit correspondences between object queries and specific targets. This learned relationship further provides supervision signals for the learning of queries. Experimental results demonstrate that our proposed method bypasses the traditional matching process, significantly enhancing training efficiency, reducing the matching latency by over 50\%, effectively eliminating the discrete matching bottleneck through differentiable correspondence learning, and also achieving superior performance compared to existing state-of-the-art methods.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025



Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
Learning Global Representation from Queries for Vectorized HD Map Construction
Oct 08, 2025The online construction of vectorized high-definition (HD) maps is a cornerstone of modern autonomous driving systems. State-of-the-art approaches, particularly those based on the DETR framework, formulate this as an instance detection problem. However, their reliance on independent, learnable object queries results in a predominantly local query perspective, neglecting the inherent global representation within HD maps. In this work, we propose \textbf{MapGR} (\textbf{G}lobal \textbf{R}epresentation learning for HD \textbf{Map} construction), an architecture designed to learn and utilize a global representations from queries. Our method introduces two synergistic modules: a Global Representation Learning (GRL) module, which encourages the distribution of all queries to better align with the global map through a carefully designed holistic segmentation task, and a Global Representation Guidance (GRG) module, which endows each individual query with explicit, global-level contextual information to facilitate its optimization. Evaluations on the nuScenes and Argoverse2 datasets validate the efficacy of our approach, demonstrating substantial improvements in mean Average Precision (mAP) compared to leading baselines.
PC-BEV: An Efficient Polar-Cartesian BEV Fusion Framework for LiDAR Semantic Segmentation
Dec 19, 2024Although multiview fusion has demonstrated potential in LiDAR segmentation, its dependence on computationally intensive point-based interactions, arising from the lack of fixed correspondences between views such as range view and Bird's-Eye View (BEV), hinders its practical deployment. This paper challenges the prevailing notion that multiview fusion is essential for achieving high performance. We demonstrate that significant gains can be realized by directly fusing Polar and Cartesian partitioning strategies within the BEV space. Our proposed BEV-only segmentation model leverages the inherent fixed grid correspondences between these partitioning schemes, enabling a fusion process that is orders of magnitude faster (170$\times$ speedup) than conventional point-based methods. Furthermore, our approach facilitates dense feature fusion, preserving richer contextual information compared to sparse point-based alternatives. To enhance scene understanding while maintaining inference efficiency, we also introduce a hybrid Transformer-CNN architecture. Extensive evaluation on the SemanticKITTI and nuScenes datasets provides compelling evidence that our method outperforms previous multiview fusion approaches in terms of both performance and inference speed, highlighting the potential of BEV-based fusion for LiDAR segmentation. Code is available at \url{https://github.com/skyshoumeng/PC-BEV.}
Make a Strong Teacher with Label Assistance: A Novel Knowledge Distillation Approach for Semantic Segmentation
Jul 18, 2024



In this paper, we introduce a novel knowledge distillation approach for the semantic segmentation task. Unlike previous methods that rely on power-trained teachers or other modalities to provide additional knowledge, our approach does not require complex teacher models or information from extra sensors. Specifically, for the teacher model training, we propose to noise the label and then incorporate it into input to effectively boost the lightweight teacher performance. To ensure the robustness of the teacher model against the introduced noise, we propose a dual-path consistency training strategy featuring a distance loss between the outputs of two paths. For the student model training, we keep it consistent with the standard distillation for simplicity. Our approach not only boosts the efficacy of knowledge distillation but also increases the flexibility in selecting teacher and student models. To demonstrate the advantages of our Label Assisted Distillation (LAD) method, we conduct extensive experiments on five challenging datasets including Cityscapes, ADE20K, PASCAL-VOC, COCO-Stuff 10K, and COCO-Stuff 164K, five popular models: FCN, PSPNet, DeepLabV3, STDC, and OCRNet, and results show the effectiveness and generalization of our approach. We posit that incorporating labels into the input, as demonstrated in our work, will provide valuable insights into related fields. Code is available at https://github.com/skyshoumeng/Label_Assisted_Distillation.
Towards Open-set Camera 3D Object Detection
Jun 25, 2024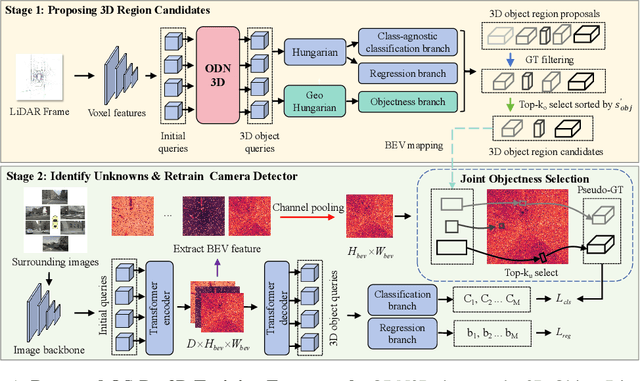

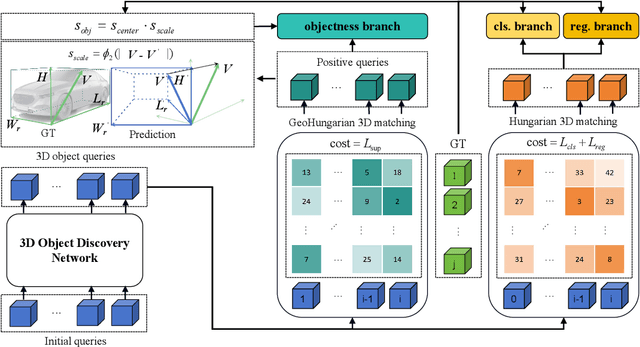

Traditional camera 3D object detectors are typically trained to recognize a predefined set of known object classes. In real-world scenarios, these detectors may encounter unknown objects outside the training categories and fail to identify them correctly. To address this gap, we present OS-Det3D (Open-set Camera 3D Object Detection), a two-stage training framework enhancing the ability of camera 3D detectors to identify both known and unknown objects. The framework involves our proposed 3D Object Discovery Network (ODN3D), which is specifically trained using geometric cues such as the location and scale of 3D boxes to discover general 3D objects. ODN3D is trained in a class-agnostic manner, and the provided 3D object region proposals inherently come with data noise. To boost accuracy in identifying unknown objects, we introduce a Joint Objectness Selection (JOS) module. JOS selects the pseudo ground truth for unknown objects from the 3D object region proposals of ODN3D by combining the ODN3D objectness and camera feature attention objectness. Experiments on the nuScenes and KITTI datasets demonstrate the effectiveness of our framework in enabling camera 3D detectors to successfully identify unknown objects while also improving their performance on known objects.
OAML: Outlier Aware Metric Learning for OOD Detection Enhancement
Jun 24, 2024



Out-of-distribution (OOD) detection methods have been developed to identify objects that a model has not seen during training. The Outlier Exposure (OE) methods use auxiliary datasets to train OOD detectors directly. However, the collection and learning of representative OOD samples may pose challenges. To tackle these issues, we propose the Outlier Aware Metric Learning (OAML) framework. The main idea of our method is to use the k-NN algorithm and Stable Diffusion model to generate outliers for training at the feature level without making any distributional assumptions. To increase feature discrepancies in the semantic space, we develop a mutual information-based contrastive learning approach for learning from OOD data effectively. Both theoretical and empirical results confirm the effectiveness of this contrastive learning technique. Furthermore, we incorporate knowledge distillation into our learning framework to prevent degradation of in-distribution classification accuracy. The combination of contrastive learning and knowledge distillation algorithms significantly enhances the performance of OOD detection. Experimental results across various datasets show that our method significantly outperforms previous OE methods.
Understanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Jun 19, 2023
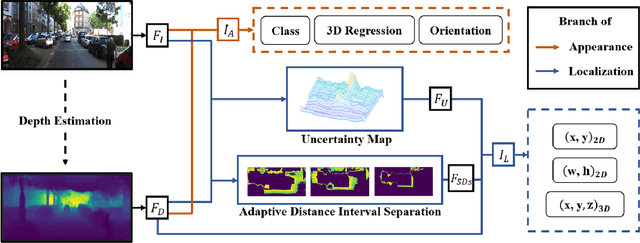
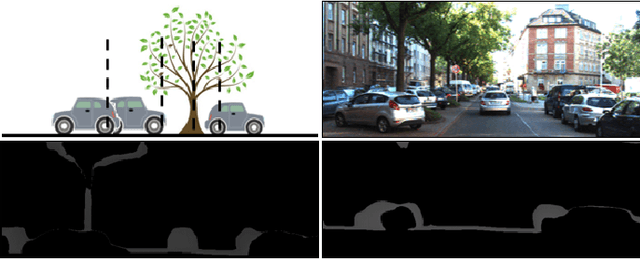
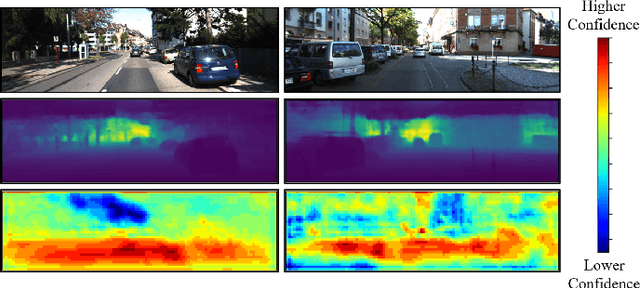
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.
Multi-to-Single Knowledge Distillation for Point Cloud Semantic Segmentation
Apr 28, 2023



3D point cloud semantic segmentation is one of the fundamental tasks for environmental understanding. Although significant progress has been made in recent years, the performance of classes with few examples or few points is still far from satisfactory. In this paper, we propose a novel multi-to-single knowledge distillation framework for the 3D point cloud semantic segmentation task to boost the performance of those hard classes. Instead of fusing all the points of multi-scans directly, only the instances that belong to the previously defined hard classes are fused. To effectively and sufficiently distill valuable knowledge from multi-scans, we leverage a multilevel distillation framework, i.e., feature representation distillation, logit distillation, and affinity distillation. We further develop a novel instance-aware affinity distillation algorithm for capturing high-level structural knowledge to enhance the distillation efficacy for hard classes. Finally, we conduct experiments on the SemanticKITTI dataset, and the results on both the validation and test sets demonstrate that our method yields substantial improvements compared with the baseline method. The code is available at \Url{https://github.com/skyshoumeng/M2SKD}.
Knowledge Distillation from 3D to Bird's-Eye-View for LiDAR Semantic Segmentation
Apr 22, 2023



LiDAR point cloud segmentation is one of the most fundamental tasks for autonomous driving scene understanding. However, it is difficult for existing models to achieve both high inference speed and accuracy simultaneously. For example, voxel-based methods perform well in accuracy, while Bird's-Eye-View (BEV)-based methods can achieve real-time inference. To overcome this issue, we develop an effective 3D-to-BEV knowledge distillation method that transfers rich knowledge from 3D voxel-based models to BEV-based models. Our framework mainly consists of two modules: the voxel-to-pillar distillation module and the label-weight distillation module. Voxel-to-pillar distillation distills sparse 3D features to BEV features for middle layers to make the BEV-based model aware of more structural and geometric information. Label-weight distillation helps the model pay more attention to regions with more height information. Finally, we conduct experiments on the SemanticKITTI dataset and Paris-Lille-3D. The results on SemanticKITTI show more than 5% improvement on the test set, especially for classes such as motorcycle and person, with more than 15% improvement. The code can be accessed at https://github.com/fengjiang5/Knowledge-Distillation-from-Cylinder3D-to-PolarNet.