 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-BEV: An Efficient Polar-Cartesian BEV Fusion Framework for LiDAR Semantic Segmentation
Dec 19, 2024Although multiview fusion has demonstrated potential in LiDAR segmentation, its dependence on computationally intensive point-based interactions, arising from the lack of fixed correspondences between views such as range view and Bird's-Eye View (BEV), hinders its practical deployment. This paper challenges the prevailing notion that multiview fusion is essential for achieving high performance. We demonstrate that significant gains can be realized by directly fusing Polar and Cartesian partitioning strategies within the BEV space. Our proposed BEV-only segmentation model leverages the inherent fixed grid correspondences between these partitioning schemes, enabling a fusion process that is orders of magnitude faster (170$\times$ speedup) than conventional point-based methods. Furthermore, our approach facilitates dense feature fusion, preserving richer contextual information compared to sparse point-based alternatives. To enhance scene understanding while maintaining inference efficiency, we also introduce a hybrid Transformer-CNN architecture. Extensive evaluation on the SemanticKITTI and nuScenes datasets provides compelling evidence that our method outperforms previous multiview fusion approaches in terms of both performance and inference speed, highlighting the potential of BEV-based fusion for LiDAR segmentation. Code is available at \url{https://github.com/skyshoumeng/PC-BEV.}
The Image Local Autoregressive Transformer
Jun 04, 2021

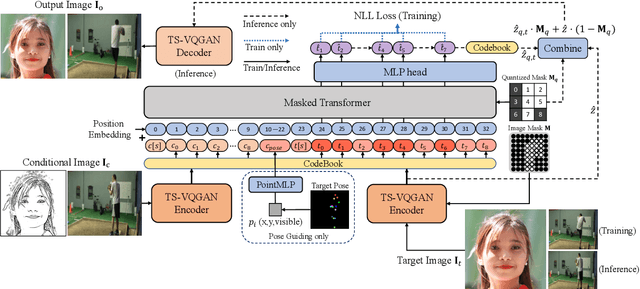
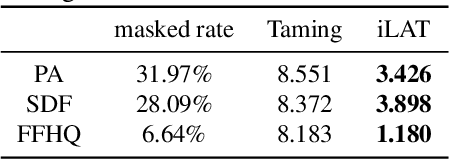
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.