 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet Prior Attention Learning in Axial Inpainting Network
Jun 07, 2022

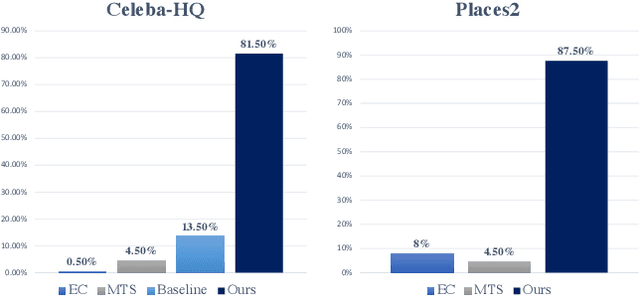
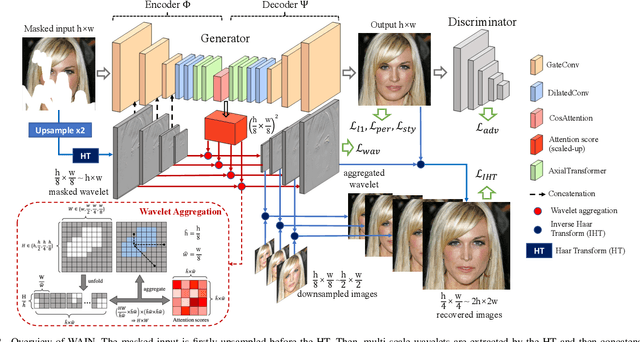
Image inpainting is the task of filling masked or unknown regions of an image with visually realistic contents, which has been remarkably improved by Deep Neural Networks (DNNs) recently. Essentially, as an inverse problem, the inpainting has the underlying challenges of reconstructing semantically coherent results without texture artifacts. Many previous efforts have been made via exploiting attention mechanisms and prior knowledge, such as edges and semantic segmentation. However, these works are still limited in practice by an avalanche of learnable prior parameters and prohibitive computational burden. To this end, we propose a novel model -- Wavelet prior attention learning in Axial Inpainting Network (WAIN), whose generator contains the encoder, decoder, as well as two key components of Wavelet image Prior Attention (WPA) and stacked multi-layer Axial-Transformers (ATs). Particularly, the WPA guides the high-level feature aggregation in the multi-scale frequency domain, alleviating the textual artifacts. Stacked ATs employ unmasked clues to help model reasonable features along with low-level features of horizontal and vertical axes, improving the semantic coherence. Extensive quantitative and qualitative experiments on Celeba-HQ and Places2 datasets are conducted to validate that our WAIN can achieve state-of-the-art performance over the competitors. The codes and models will be released.
The Image Local Autoregressive Transformer
Jun 04, 2021

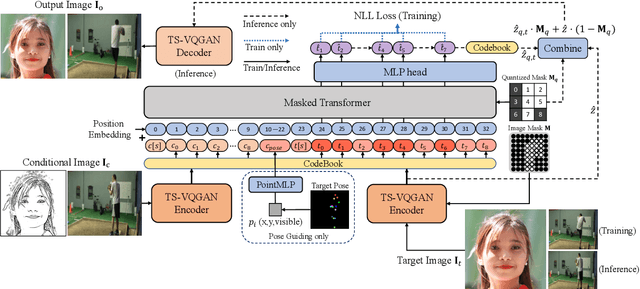
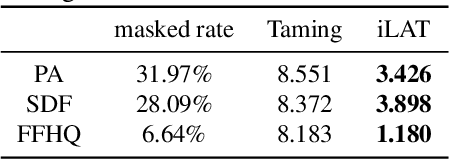
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.