 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Paper and Code
Jun 19, 2023
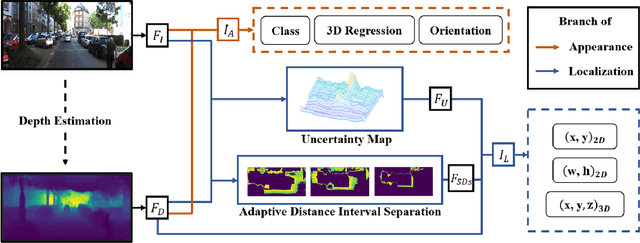
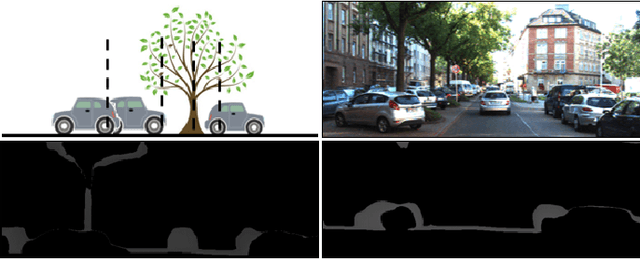
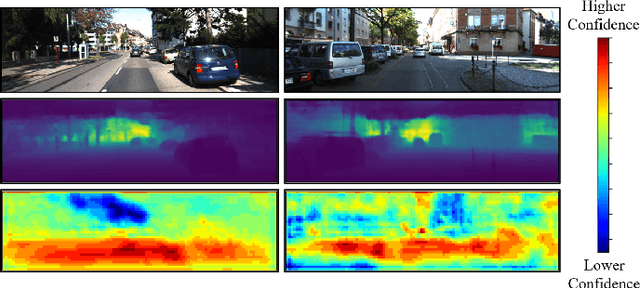
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.