 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask Attention Networks: Rethinking and Strengthen Transformer
Paper and Code
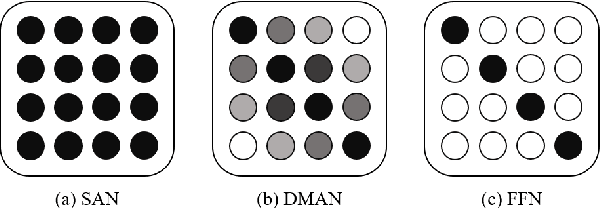
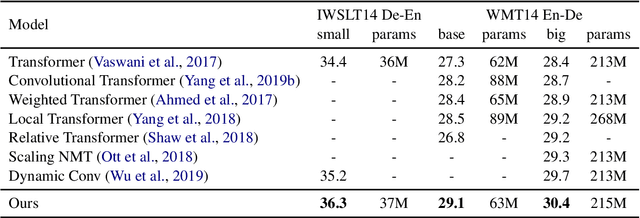
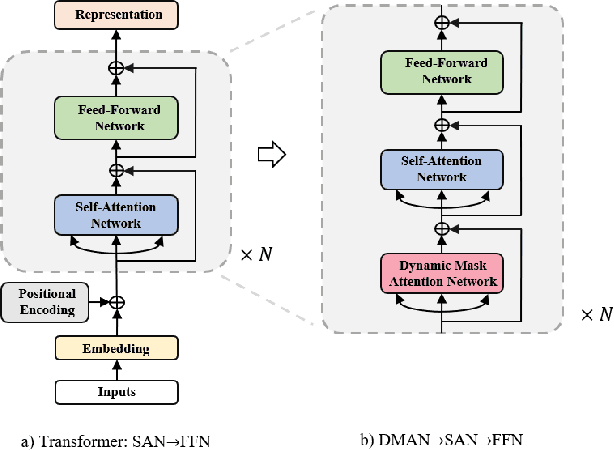
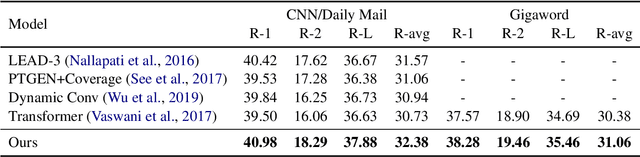
Transformer is an attention-based neural network, which consists of two sublayers, namely, Self-Attention Network (SAN) and Feed-Forward Network (FFN). Existing research explores to enhance the two sublayers separately to improve the capability of Transformer for text representation. In this paper, we present a novel understanding of SAN and FFN as Mask Attention Networks (MANs) and show that they are two special cases of MANs with static mask matrices. However, their static mask matrices limit the capability for localness modeling in text representation learning. We therefore introduce a new layer named dynamic mask attention network (DMAN) with a learnable mask matrix which is able to model localness adaptively. To incorporate advantages of DMAN, SAN, and FFN, we propose a sequential layered structure to combine the three types of layers. Extensive experiments on various tasks, including neural machine translation and text summarization demonstrate that our model outperforms the original Transformer.