 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Paced Mixed Distillation Method for Non-Autoregressive Generation
Paper and Code
May 23, 2022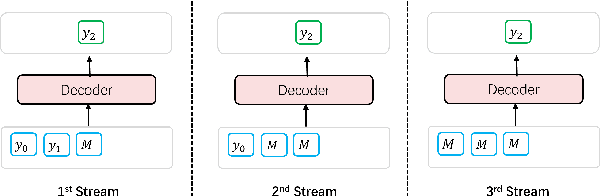


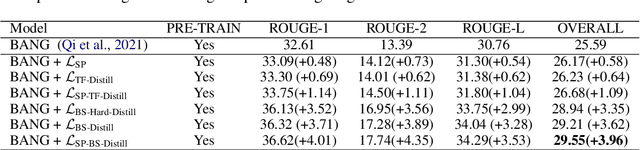
Non-Autoregressive generation is a sequence generation paradigm, which removes the dependency between target tokens. It could efficiently reduce the text generation latency with parallel decoding in place of token-by-token sequential decoding. However, due to the known multi-modality problem, Non-Autoregressive (NAR) models significantly under-perform Auto-regressive (AR) models on various language generation tasks. Among the NAR models, BANG is the first large-scale pre-training model on English un-labeled raw text corpus. It considers different generation paradigms as its pre-training tasks including Auto-regressive (AR), Non-Autoregressive (NAR), and semi-Non-Autoregressive (semi-NAR) information flow with multi-stream strategy. It achieves state-of-the-art performance without any distillation techniques. However, AR distillation has been shown to be a very effective solution for improving NAR performance. In this paper, we propose a novel self-paced mixed distillation method to further improve the generation quality of BANG. Firstly, we propose the mixed distillation strategy based on the AR stream knowledge. Secondly, we encourage the model to focus on the samples with the same modality by self-paced learning. The proposed self-paced mixed distillation algorithm improves the generation quality and has no influence on the inference latency. We carry out extensive experiments on summarization and question generation tasks to validate the effectiveness. To further illustrate the commercial value of our approach, we conduct experiments on three generation tasks in real-world advertisements applications. Experimental results on commercial data show the effectiveness of the proposed model. Compared with BANG, it achieves significant BLEU score improvement. On the other hand, compared with auto-regressive generation method, it achieves more than 7x speedup.