 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
Paper and Code
Apr 27, 2022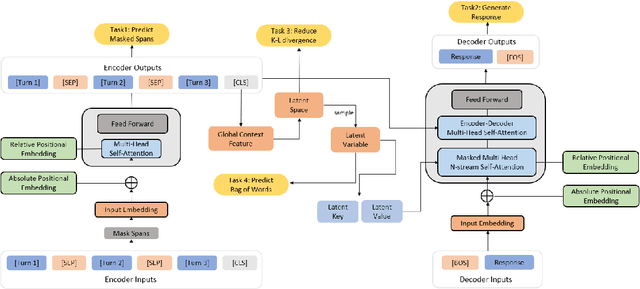
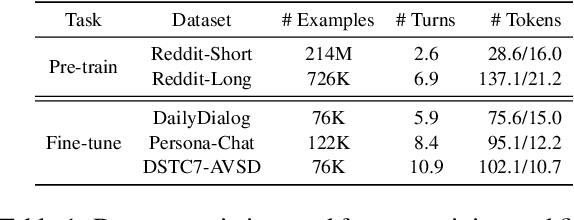
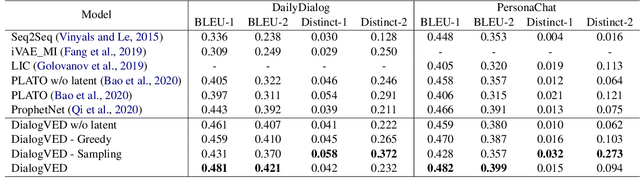
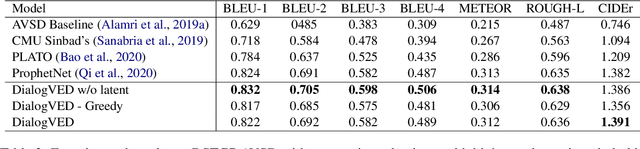
Dialog response generation in open domain is an important research topic where the main challenge is to generate relevant and diverse responses. In this paper, we propose a new dialog pre-training framework called DialogVED, which introduces continuous latent variables into the enhanced encoder-decoder pre-training framework to increase the relevance and diversity of responses. With the help of a large dialog corpus (Reddit), we pre-train the model using the following 4 tasks, used in training language models (LMs) and Variational Autoencoders (VAEs) literature: 1) masked language model; 2) response generation; 3) bag-of-words prediction; and 4) KL divergence reduction. We also add additional parameters to model the turn structure in dialogs to improve the performance of the pre-trained model. We conduct experiments on PersonaChat, DailyDialog, and DSTC7-AVSD benchmarks for response generation. Experimental results show that our model achieves the new state-of-the-art results on all these datasets.