 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrackGAN: A Labor-Light Crack Detection Approach Using Industrial Pavement Images Based on Generative Adversarial Learning
Paper and Code
Sep 18, 2019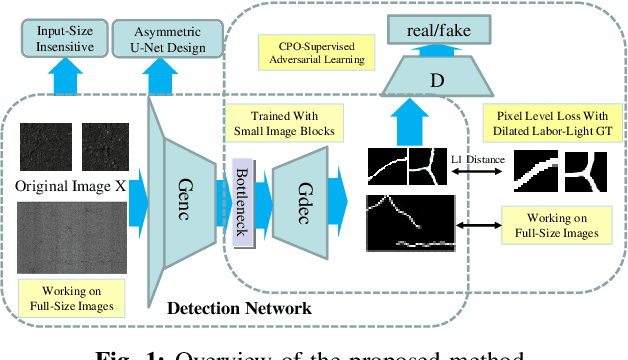
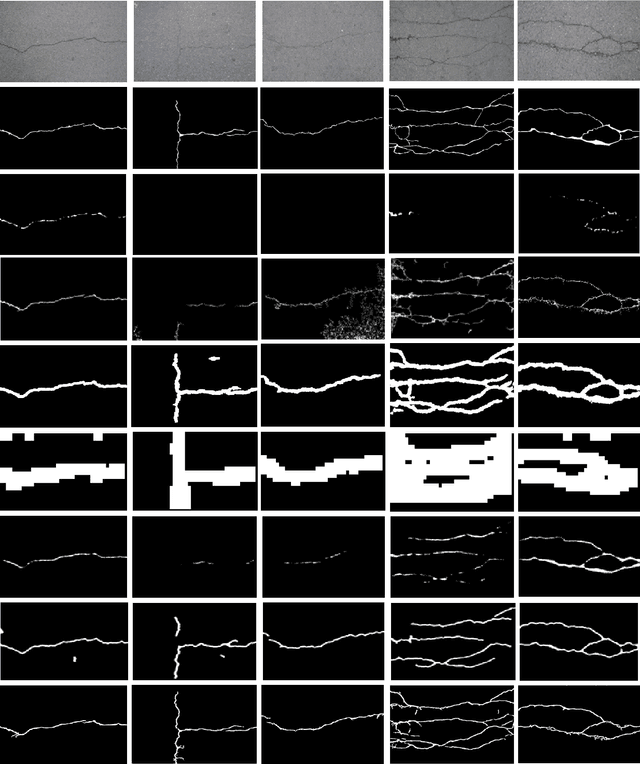
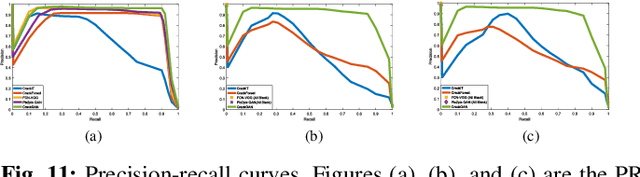

Fully convolutional network is a powerful tool for per-pixel semantic segmentation/detection. However, it is problematic when coping with crack detection using industrial pavement images: the network may easily "converge" to the status that treats all the pixels as background (BG) and still achieves a very good loss, named "All Black" phenomenon, due to the data imbalance and the unavailability of accurate ground truths (GTs). To tackle this problem, we introduce crack-patch-only (CPO) supervision and generative adversarial learning for end-to-end training, which forces the network to always produce crack-GT images while reserves both crack and BG-image translation abilities by feeding a larger-size crack image into an asymmetric U-shape generator to overcome the "All Black" issue. The proposed approach is validated using four crack datasets; and achieves state-of-the-art performance comparing with that of the recently published works in efficiency and accuracy.