 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Slice Low-Rank Tensor Decomposition Based Multi-Atlas Segmentation: Application to Automatic Pathological Liver CT Segmentation
Feb 24, 2021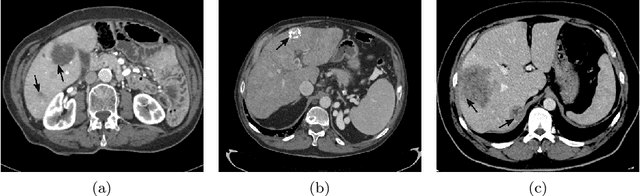
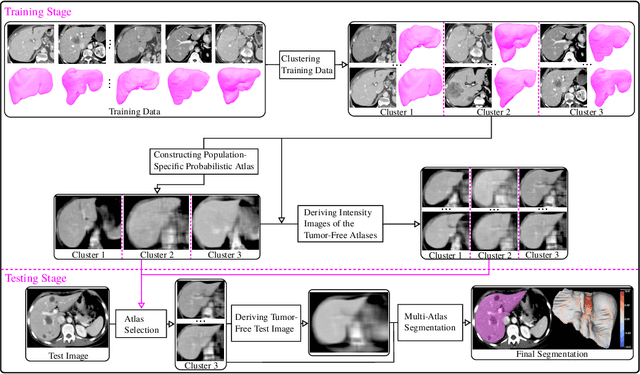

Liver segmentation from abdominal CT images is an essential step for liver cancer computer-aided diagnosis and surgical planning. However, both the accuracy and robustness of existing liver segmentation methods cannot meet the requirements of clinical applications. In particular, for the common clinical cases where the liver tissue contains major pathology, current segmentation methods show poor performance. In this paper, we propose a novel low-rank tensor decomposition (LRTD) based multi-atlas segmentation (MAS) framework that achieves accurate and robust pathological liver segmentation of CT images. Firstly, we propose a multi-slice LRTD scheme to recover the underlying low-rank structure embedded in 3D medical images. It performs the LRTD on small image segments consisting of multiple consecutive image slices. Then, we present an LRTD-based atlas construction method to generate tumor-free liver atlases that mitigates the performance degradation of liver segmentation due to the presence of tumors. Finally, we introduce an LRTD-based MAS algorithm to derive patient-specific liver atlases for each test image, and to achieve accurate pairwise image registration and label propagation. Extensive experiments on three public databases of pathological liver cases validate the effectiveness of the proposed method. Both qualitative and quantitative results demonstrate that, in the presence of major pathology, the proposed method is more accurate and robust than state-of-the-art methods.
CrackGAN: A Labor-Light Crack Detection Approach Using Industrial Pavement Images Based on Generative Adversarial Learning
Sep 18, 2019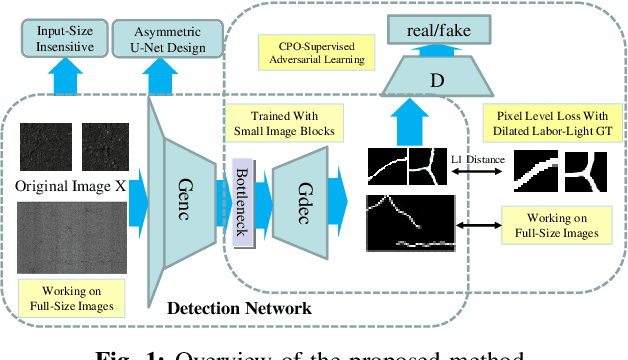
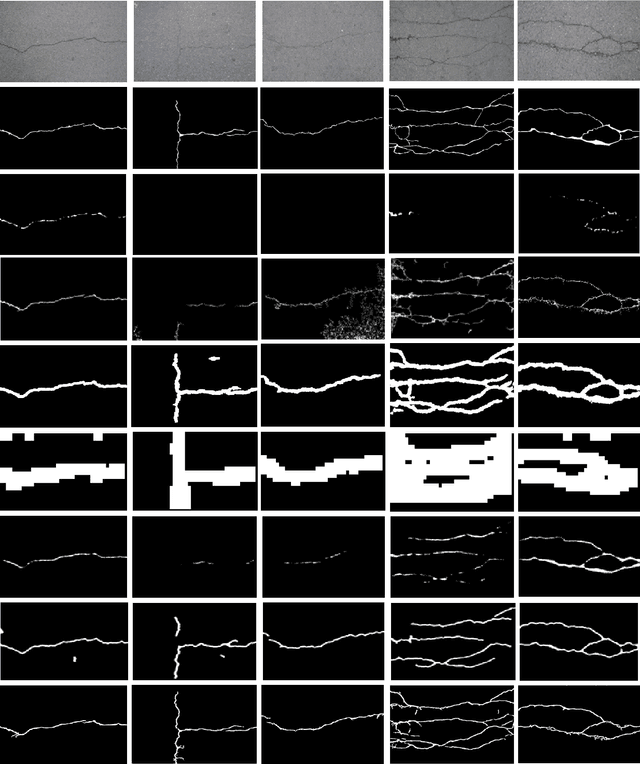
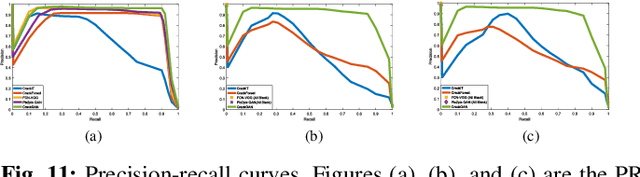

Fully convolutional network is a powerful tool for per-pixel semantic segmentation/detection. However, it is problematic when coping with crack detection using industrial pavement images: the network may easily "converge" to the status that treats all the pixels as background (BG) and still achieves a very good loss, named "All Black" phenomenon, due to the data imbalance and the unavailability of accurate ground truths (GTs). To tackle this problem, we introduce crack-patch-only (CPO) supervision and generative adversarial learning for end-to-end training, which forces the network to always produce crack-GT images while reserves both crack and BG-image translation abilities by feeding a larger-size crack image into an asymmetric U-shape generator to overcome the "All Black" issue. The proposed approach is validated using four crack datasets; and achieves state-of-the-art performance comparing with that of the recently published works in efficiency and accuracy.