 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Boxes: Boosting End-to-End Scene Text Recognition by Adjusting Annotated Bounding Boxes via Reinforcement Learning
Jul 26, 2022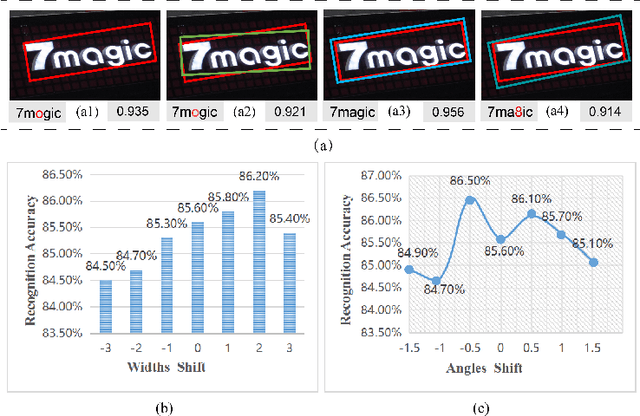

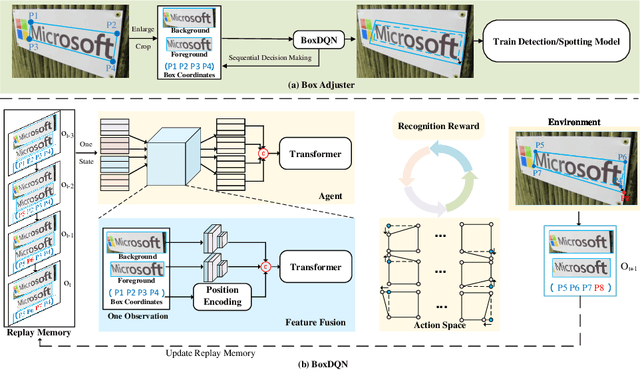
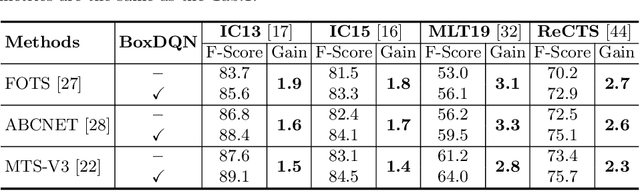
Text detection and recognition are essential components of a modern OCR system. Most OCR approaches attempt to obtain accurate bounding boxes of text at the detection stage, which is used as the input of the text recognition stage. We observe that when using tight text bounding boxes as input, a text recognizer frequently fails to achieve optimal performance due to the inconsistency between bounding boxes and deep representations of text recognition. In this paper, we propose Box Adjuster, a reinforcement learning-based method for adjusting the shape of each text bounding box to make it more compatible with text recognition models. Additionally, when dealing with cross-domain problems such as synthetic-to-real, the proposed method significantly reduces mismatches in domain distribution between the source and target domains. Experiments demonstrate that the performance of end-to-end text recognition systems can be improved when using the adjusted bounding boxes as the ground truths for training. Specifically, on several benchmark datasets for scene text understanding, the proposed method outperforms state-of-the-art text spotters by an average of 2.0% F-Score on end-to-end text recognition tasks and 4.6% F-Score on domain adaptation tasks.