 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Mar 17, 2025Recent advancements in Large Language Models (LLMs) have demonstrated enhanced reasoning capabilities, evolving from Chain-of-Thought (CoT) prompting to advanced, product-oriented solutions like OpenAI o1. During our re-implementation of this model, we noticed that in multimodal tasks requiring visual input (e.g., geometry problems), Multimodal LLMs (MLLMs) struggle to maintain focus on the visual information, in other words, MLLMs suffer from a gradual decline in attention to visual information as reasoning progresses, causing text-over-relied outputs. To investigate this, we ablate image inputs during long-chain reasoning. Concretely, we truncate the reasoning process midway, then re-complete the reasoning process with the input image removed. We observe only a ~2% accuracy drop on MathVista's test-hard subset, revealing the model's textual outputs dominate the following reasoning process. Motivated by this, we propose Take-along Visual Conditioning (TVC), a strategy that shifts image input to critical reasoning stages and compresses redundant visual tokens via dynamic pruning. This methodology helps the model retain attention to the visual components throughout the reasoning. Our approach achieves state-of-the-art performance on average across five mathematical reasoning benchmarks (+3.4% vs previous sota), demonstrating the effectiveness of TVC in enhancing multimodal reasoning systems.
Discovering More Effective Tensor Network Structure Search Algorithms via Large Language Models (LLMs)
Feb 04, 2024



Tensor network structure search (TN-SS), aiming at searching for suitable tensor network (TN) structures in representing high-dimensional problems, largely promotes the efficacy of TN in various machine learning applications. Nonetheless, finding a satisfactory TN structure using existing algorithms remains challenging. To develop more effective algorithms and avoid the human labor-intensive development process, we explore the knowledge embedded in large language models (LLMs) for the automatic design of TN-SS algorithms. Our approach, dubbed GPTN-SS, leverages an elaborate crafting LLM-based prompting system that operates in an evolutionary-like manner. The experimental results, derived from real-world data, demonstrate that GPTN-SS can effectively leverage the insights gained from existing methods to develop novel TN-SS algorithms that achieve a better balance between exploration and exploitation. These algorithms exhibit superior performance in searching the high-quality TN structures for natural image compression and model parameters compression while also demonstrating generalizability in their performance.
Exploring Data Augmentations on Self-/Semi-/Fully- Supervised Pre-trained Models
Oct 28, 2023Data augmentation has become a standard component of vision pre-trained models to capture the invariance between augmented views. In practice, augmentation techniques that mask regions of a sample with zero/mean values or patches from other samples are commonly employed in pre-trained models with self-/semi-/fully-supervised contrastive losses. However, the underlying mechanism behind the effectiveness of these augmentation techniques remains poorly explored. To investigate the problems, we conduct an empirical study to quantify how data augmentation affects performance. Concretely, we apply 4 types of data augmentations termed with Random Erasing, CutOut, CutMix and MixUp to a series of self-/semi-/fully- supervised pre-trained models. We report their performance on vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. We then explicitly evaluate the invariance and diversity of the feature embedding. We observe that: 1) Masking regions of the images decreases the invariance of the learned feature embedding while providing a more considerable diversity. 2) Manual annotations do not change the invariance or diversity of the learned feature embedding. 3) The MixUp approach improves the diversity significantly, with only a marginal decrease in terms of the invariance.
What Can Simple Arithmetic Operations Do for Temporal Modeling?
Jul 18, 2023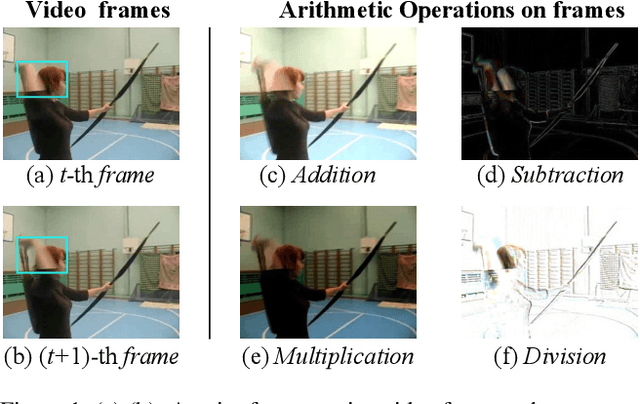
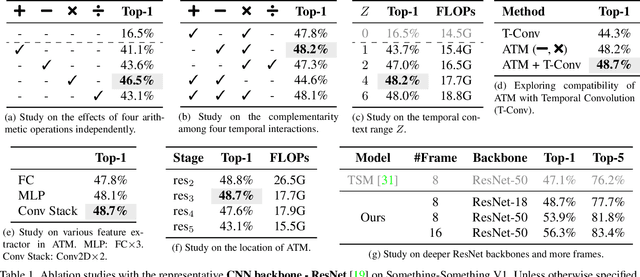
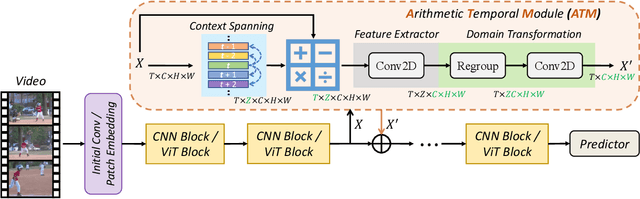

Temporal modeling plays a crucial role in understanding video content. To tackle this problem, previous studies built complicated temporal relations through time sequence thanks to the development of computationally powerful devices. In this work, we explore the potential of four simple arithmetic operations for temporal modeling. Specifically, we first capture auxiliary temporal cues by computing addition, subtraction, multiplication, and division between pairs of extracted frame features. Then, we extract corresponding features from these cues to benefit the original temporal-irrespective domain. We term such a simple pipeline as an Arithmetic Temporal Module (ATM), which operates on the stem of a visual backbone with a plug-andplay style. We conduct comprehensive ablation studies on the instantiation of ATMs and demonstrate that this module provides powerful temporal modeling capability at a low computational cost. Moreover, the ATM is compatible with both CNNs- and ViTs-based architectures. Our results show that ATM achieves superior performance over several popular video benchmarks. Specifically, on Something-Something V1, V2 and Kinetics-400, we reach top-1 accuracy of 65.6%, 74.6%, and 89.4% respectively. The code is available at https://github.com/whwu95/ATM.
Rethinking Prototypical Contrastive Learning through Alignment, Uniformity and Correlation
Oct 18, 2022

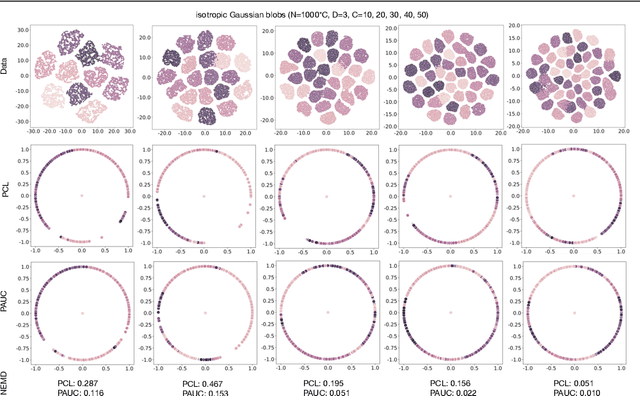

Contrastive self-supervised learning (CSL) with a prototypical regularization has been introduced in learning meaningful representations for downstream tasks that require strong semantic information. However, to optimize CSL with a loss that performs the prototypical regularization aggressively, e.g., the ProtoNCE loss, might cause the "coagulation" of examples in the embedding space. That is, the intra-prototype diversity of samples collapses to trivial solutions for their prototype being well-separated from others. Motivated by previous works, we propose to mitigate this phenomenon by learning Prototypical representation through Alignment, Uniformity and Correlation (PAUC). Specifically, the ordinary ProtoNCE loss is revised with: (1) an alignment loss that pulls embeddings from positive prototypes together; (2) a uniformity loss that distributes the prototypical level features uniformly; (3) a correlation loss that increases the diversity and discriminability between prototypical level features. We conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method in improving the quality of prototypical contrastive representations. Particularly, in the classification down-stream tasks with linear probes, our proposed method outperforms the state-of-the-art instance-wise and prototypical contrastive learning methods on the ImageNet-100 dataset by 2.96% and the ImageNet-1K dataset by 2.46% under the same settings of batch size and epochs.
Design of the topology for contrastive visual-textual alignment
Sep 05, 2022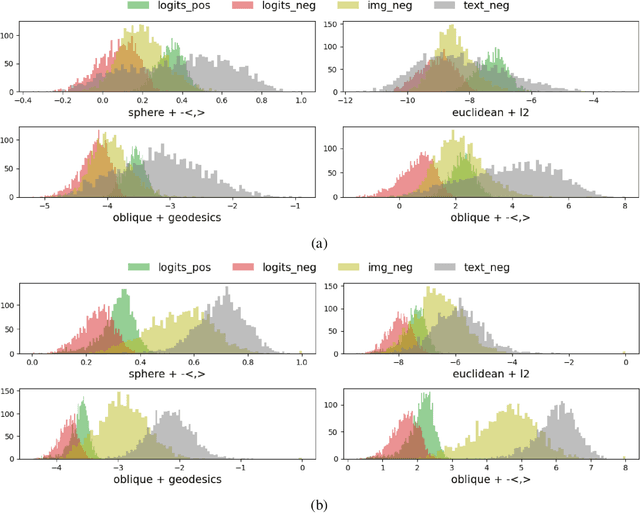



Pre-training weakly related image-text pairs in the contrastive style shows great power in learning semantic aligning cross-modal models. The common choice to measure the distance between the feature representations of the image-text pairs is the cosine similarity, which can be considered as the negative inner product of features embedded on a sphere mathematically. While such topology benefits from the low computational resources consumption and a properly defined uniformity, typically, there are two major drawbacks when applied. First, it is vulnerable to the semantic ambiguity phenomenon resulting from the noise in the weakly-related image-text pairs. Second, the learning progress is unstable and fragile at the beginning. Although, in the practice of former studies, a learnable softmax temperature parameter and a long warmup scheme are employed to meliorate the training progress, still there lacks an in-depth analysis of these problems. In this work, we discuss the desired properties of the topology and its endowed distance function for the embedding vectors of feature representations from the view of optimization. We then propose a rather simple solution to improve the aforementioned problem. That is, we map the feature representations onto the oblique manifold endowed with the negative inner product as the distance function. In the experimental analysis, we show that we can improve the baseline performance by a large margin (e.g. 4% in the zero-shot image to text retrieval task) by changing only two lines of the training codes.
Siamese Prototypical Contrastive Learning
Aug 18, 2022
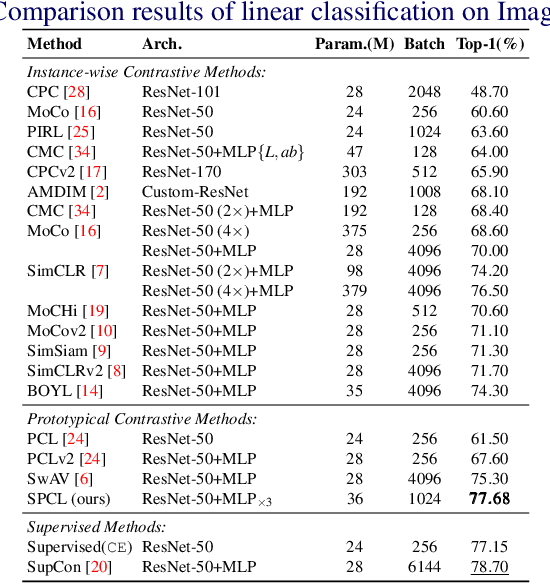

Contrastive Self-supervised Learning (CSL) is a practical solution that learns meaningful visual representations from massive data in an unsupervised approach. The ordinary CSL embeds the features extracted from neural networks onto specific topological structures. During the training progress, the contrastive loss draws the different views of the same input together while pushing the embeddings from different inputs apart. One of the drawbacks of CSL is that the loss term requires a large number of negative samples to provide better mutual information bound ideally. However, increasing the number of negative samples by larger running batch size also enhances the effects of false negatives: semantically similar samples are pushed apart from the anchor, hence downgrading downstream performance. In this paper, we tackle this problem by introducing a simple but effective contrastive learning framework. The key insight is to employ siamese-style metric loss to match intra-prototype features, while increasing the distance between inter-prototype features. We conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method on improving the quality of visual representations. Specifically, our unsupervised pre-trained ResNet-50 with a linear probe, out-performs the fully-supervised trained version on the ImageNet-1K dataset.
Transferring Textual Knowledge for Visual Recognition
Jul 04, 2022



Transferring knowledge from task-agnostic pre-trained deep models for downstream tasks is an important topic in computer vision research. Along with the growth of computational capacity, we now have open-source Vision-Language pre-trained models in large scales of the model architecture and amount of data. In this study, we focus on transferring knowledge for vision classification tasks. Conventional methods randomly initialize the linear classifier head for vision classification, but they leave the usage of the text encoder for downstream visual recognition tasks undiscovered. In this paper, we revise the role of the linear classifier and replace the classifier with the embedded language representations of the object categories. These language representations are initialized from the text encoder of the vision-language pre-trained model to further utilize its well-pretrained language model parameters. The empirical study shows that our method improves both the performance and the training speed of video classification, with a negligible change in the model. In particular, our paradigm achieves the state-of-the-art accuracy of 87.3% on Kinetics-400.
On the Memory Mechanism of Tensor-Power Recurrent Models
Mar 02, 2021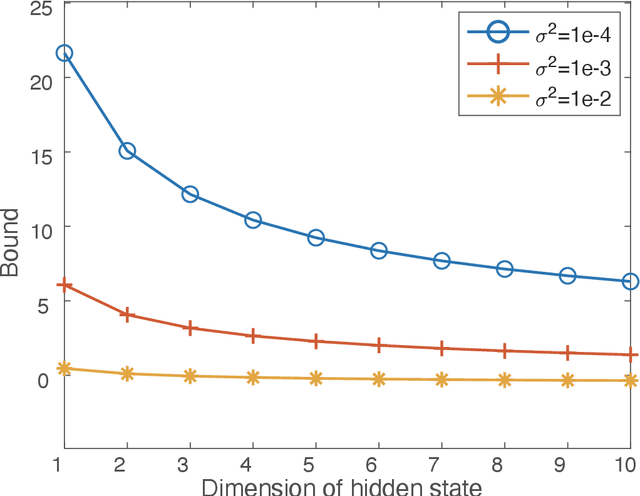
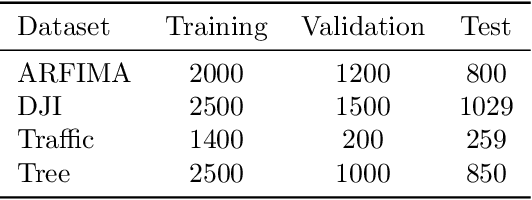
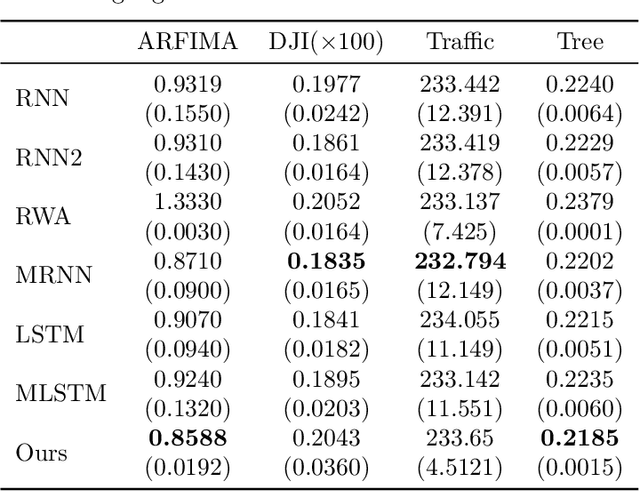

Tensor-power (TP) recurrent model is a family of non-linear dynamical systems, of which the recurrence relation consists of a p-fold (a.k.a., degree-p) tensor product. Despite such the model frequently appears in the advanced recurrent neural networks (RNNs), to this date there is limited study on its memory property, a critical characteristic in sequence tasks. In this work, we conduct a thorough investigation of the memory mechanism of TP recurrent models. Theoretically, we prove that a large degree p is an essential condition to achieve the long memory effect, yet it would lead to unstable dynamical behaviors. Empirically, we tackle this issue by extending the degree p from discrete to a differentiable domain, such that it is efficiently learnable from a variety of datasets. Taken together, the new model is expected to benefit from the long memory effect in a stable manner. We experimentally show that the proposed model achieves competitive performance compared to various advanced RNNs in both the single-cell and seq2seq architectures.
Improving Head Pose Estimation with a Combined Loss and Bounding Box Margin Adjustment
May 14, 2019
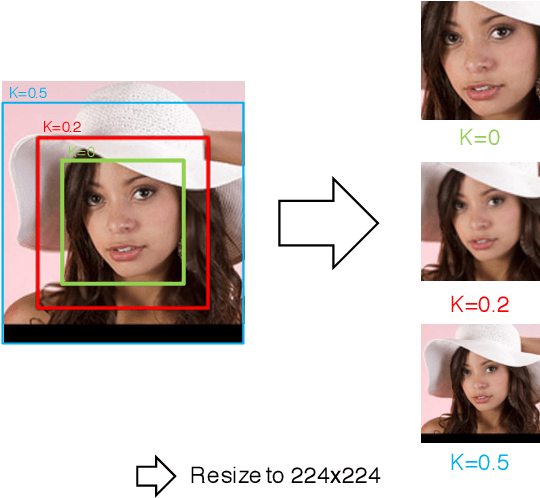
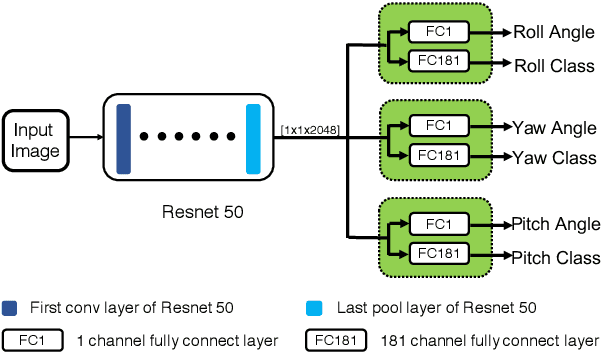
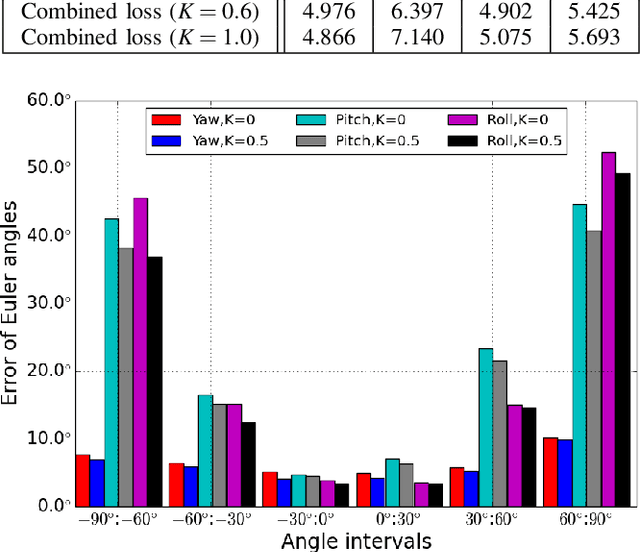
We address a problem of estimating pose of a person's head from its RGB image. The employment of CNNs for the problem has contributed to significant improvement in accuracy in recent works. However, we show that the following two methods, despite their simplicity, can attain further improvement: (i) proper adjustment of the margin of bounding box of a detected face, and (ii) choice of loss functions. We show that the integration of these two methods achieve the new state-of-the-art on standard benchmark datasets for in-the-wild head pose estimation.