 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicateAnyScene: Zero-Shot Video-to-3D Composition via Textual-Visual-Spatial Alignment
Apr 12, 2026Humans exhibit an innate capacity to rapidly perceive and segment objects from video observations, and even mentally assemble them into structured 3D scenes. Replicating such capability, termed compositional 3D reconstruction, is pivotal for the advancement of Spatial Intelligence and Embodied AI. However, existing methods struggle to achieve practical deployment due to the insufficient integration of cross-modal information, leaving them dependent on manual object prompting, reliant on auxiliary visual inputs, and restricted to overly simplistic scenes by training biases. To address these limitations, we propose ReplicateAnyScene, a framework capable of fully automated and zero-shot transformation of casually captured videos into compositional 3D scenes. Specifically, our pipeline incorporates a five-stage cascade to extract and structurally align generic priors from vision foundation models across textual, visual, and spatial dimensions, grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility of the constructed scenes. To facilitate a more comprehensive evaluation of this task, we further introduce the C3DR benchmark to assess reconstruction quality from diverse aspects. Extensive experiments demonstrate the superiority of our method over existing baselines in generating high-quality compositional 3D scenes.
OnlineX: Unified Online 3D Reconstruction and Understanding with Active-to-Stable State Evolution
Mar 03, 2026Recent advances in generalizable 3D Gaussian Splatting (3DGS) have enabled rapid 3D scene reconstruction within seconds, eliminating the need for per-scene optimization. However, existing methods primarily follow an offline reconstruction paradigm, lacking the capacity for continuous reconstruction, which limits their applicability to online scenarios such as robotics and VR/AR. In this paper, we introduce OnlineX, a feed-forward framework that reconstructs both 3D visual appearance and language fields in an online manner using only streaming images. A key challenge in online formulation is the cumulative drift issue, which is rooted in the fundamental conflict between two opposing roles of the memory state: an active role that constantly refreshes to capture high-frequency local geometry, and a stable role that conservatively accumulates and preserves the long-term global structure. To address this, we introduce a decoupled active-to-stable state evolution paradigm. Our framework decouples the memory state into a dedicated active state and a persistent stable state, and then cohesively fuses the information from the former into the latter to achieve both fidelity and stability. Moreover, we jointly model visual appearance and language fields and incorporate an implicit Gaussian fusion module to enhance reconstruction quality. Experiments on mainstream datasets demonstrate that our method consistently outperforms prior work in novel view synthesis and semantic understanding, showcasing robust performance across input sequences of varying lengths with real-time inference speed.
SimRecon: SimReady Compositional Scene Reconstruction from Real Videos
Mar 03, 2026Compositional scene reconstruction seeks to create object-centric representations rather than holistic scenes from real-world videos, which is natively applicable for simulation and interaction. Conventional compositional reconstruction approaches primarily emphasize on visual appearance and show limited generalization ability to real-world scenarios. In this paper, we propose SimRecon, a framework that realizes a "Perception-Generation-Simulation" pipeline towards cluttered scene reconstruction, which first conducts scene-level semantic reconstruction from video input, then performs single-object generation, and finally assembles these assets in the simulator. However, naively combining these three stages leads to visual infidelity of generated assets and physical implausibility of the final scene, a problem particularly severe for complex scenes. Thus, we further propose two bridging modules between the three stages to address this problem. To be specific, for the transition from Perception to Generation, critical for visual fidelity, we introduce Active Viewpoint Optimization, which actively searches in 3D space to acquire optimal projected images as conditions for single-object completion. Moreover, for the transition from Generation to Simulation, essential for physical plausibility, we propose a Scene Graph Synthesizer, which guides the construction from scratch in 3D simulators, mirroring the native, constructive principle of the real world. Extensive experiments on the ScanNet dataset validate our method's superior performance over previous state-of-the-art approaches.
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.
Anyview: Generalizable Indoor 3D Object Detection with Variable Frames
Oct 09, 2023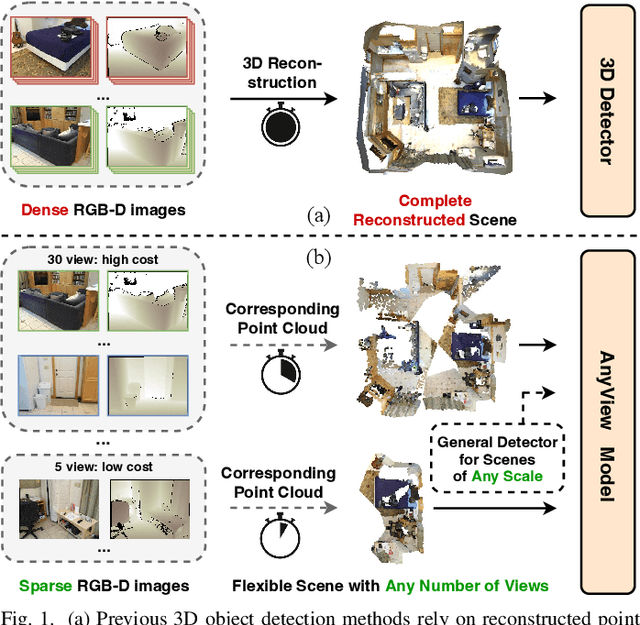
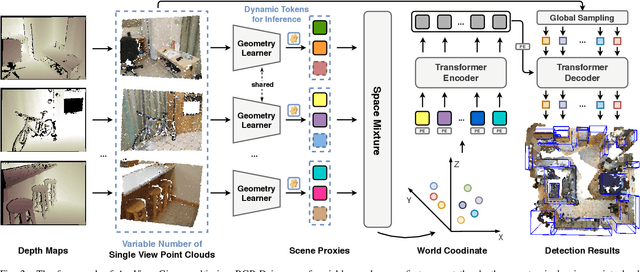

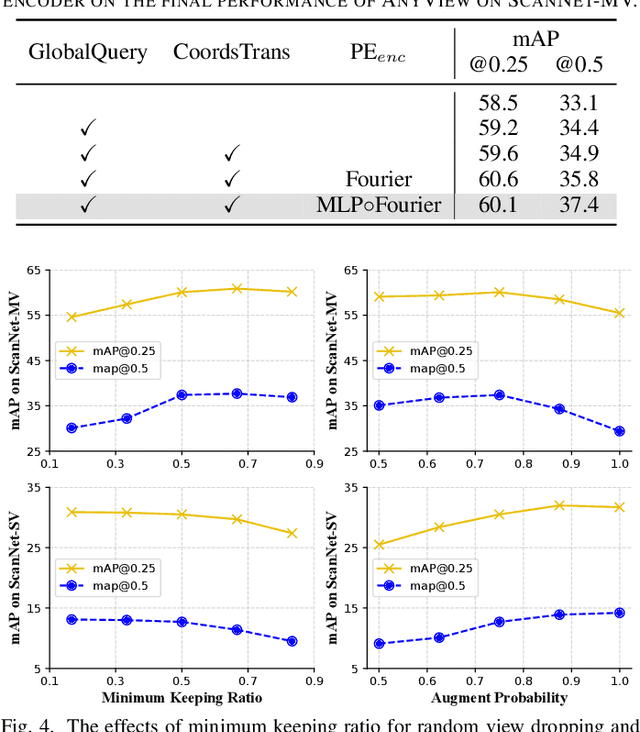
In this paper, we propose a novel network framework for indoor 3D object detection to handle variable input frame numbers in practical scenarios. Existing methods only consider fixed frames of input data for a single detector, such as monocular RGB-D images or point clouds reconstructed from dense multi-view RGB-D images. While in practical application scenes such as robot navigation and manipulation, the raw input to the 3D detectors is the RGB-D images with variable frame numbers instead of the reconstructed scene point cloud. However, the previous approaches can only handle fixed frame input data and have poor performance with variable frame input. In order to facilitate 3D object detection methods suitable for practical tasks, we present a novel 3D detection framework named AnyView for our practical applications, which generalizes well across different numbers of input frames with a single model. To be specific, we propose a geometric learner to mine the local geometric features of each input RGB-D image frame and implement local-global feature interaction through a designed spatial mixture module. Meanwhile, we further utilize a dynamic token strategy to adaptively adjust the number of extracted features for each frame, which ensures consistent global feature density and further enhances the generalization after fusion. Extensive experiments on the ScanNet dataset show our method achieves both great generalizability and high detection accuracy with a simple and clean architecture containing a similar amount of parameters with the baselines.