 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGaussian: Real-Time Camera Pose Estimation via Feed-Forward 3D Gaussian Splatting Inversion
Nov 18, 2025Recent trends in SLAM and visual navigation have embraced 3D Gaussians as the preferred scene representation, highlighting the importance of estimating camera poses from a single image using a pre-built Gaussian model. However, existing approaches typically rely on an iterative \textit{render-compare-refine} loop, where candidate views are first rendered using NeRF or Gaussian Splatting, then compared against the target image, and finally, discrepancies are used to update the pose. This multi-round process incurs significant computational overhead, hindering real-time performance in robotics. In this paper, we propose iGaussian, a two-stage feed-forward framework that achieves real-time camera pose estimation through direct 3D Gaussian inversion. Our method first regresses a coarse 6DoF pose using a Gaussian Scene Prior-based Pose Regression Network with spatial uniform sampling and guided attention mechanisms, then refines it through feature matching and multi-model fusion. The key contribution lies in our cross-correlation module that aligns image embeddings with 3D Gaussian attributes without differentiable rendering, coupled with a Weighted Multiview Predictor that fuses features from Multiple strategically sampled viewpoints. Experimental results on the NeRF Synthetic, Mip-NeRF 360, and T\&T+DB datasets demonstrate a significant performance improvement over previous methods, reducing median rotation errors to 0.2° while achieving 2.87 FPS tracking on mobile robots, which is an impressive 10 times speedup compared to optimization-based approaches. Code: https://github.com/pythongod-exe/iGaussian
Pseudo Depth Meets Gaussian: A Feed-forward RGB SLAM Baseline
Aug 06, 2025Incrementally recovering real-sized 3D geometry from a pose-free RGB stream is a challenging task in 3D reconstruction, requiring minimal assumptions on input data. Existing methods can be broadly categorized into end-to-end and visual SLAM-based approaches, both of which either struggle with long sequences or depend on slow test-time optimization and depth sensors. To address this, we first integrate a depth estimator into an RGB-D SLAM system, but this approach is hindered by inaccurate geometric details in predicted depth. Through further investigation, we find that 3D Gaussian mapping can effectively solve this problem. Building on this, we propose an online 3D reconstruction method using 3D Gaussian-based SLAM, combined with a feed-forward recurrent prediction module to directly infer camera pose from optical flow. This approach replaces slow test-time optimization with fast network inference, significantly improving tracking speed. Additionally, we introduce a local graph rendering technique to enhance robustness in feed-forward pose prediction. Experimental results on the Replica and TUM-RGBD datasets, along with a real-world deployment demonstration, show that our method achieves performance on par with the state-of-the-art SplaTAM, while reducing tracking time by more than 90\%.
EmbodiedSAM: Online Segment Any 3D Thing in Real Time
Aug 21, 2024


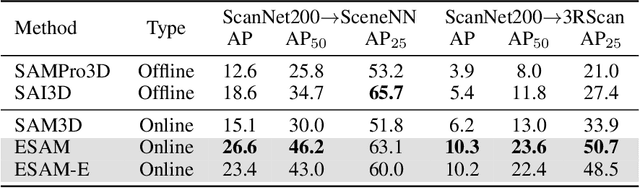
Embodied tasks require the agent to fully understand 3D scenes simultaneously with its exploration, so an online, real-time, fine-grained and highly-generalized 3D perception model is desperately needed. Since high-quality 3D data is limited, directly training such a model in 3D is almost infeasible. Meanwhile, vision foundation models (VFM) has revolutionized the field of 2D computer vision with superior performance, which makes the use of VFM to assist embodied 3D perception a promising direction. However, most existing VFM-assisted 3D perception methods are either offline or too slow that cannot be applied in practical embodied tasks. In this paper, we aim to leverage Segment Anything Model (SAM) for real-time 3D instance segmentation in an online setting. This is a challenging problem since future frames are not available in the input streaming RGB-D video, and an instance may be observed in several frames so object matching between frames is required. To address these challenges, we first propose a geometric-aware query lifting module to represent the 2D masks generated by SAM by 3D-aware queries, which is then iteratively refined by a dual-level query decoder. In this way, the 2D masks are transferred to fine-grained shapes on 3D point clouds. Benefit from the query representation for 3D masks, we can compute the similarity matrix between the 3D masks from different views by efficient matrix operation, which enables real-time inference. Experiments on ScanNet, ScanNet200, SceneNN and 3RScan show our method achieves leading performance even compared with offline methods. Our method also demonstrates great generalization ability in several zero-shot dataset transferring experiments and show great potential in open-vocabulary and data-efficient setting. Code and demo are available at https://xuxw98.github.io/ESAM/, with only one RTX 3090 GPU required for training and evaluation.
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.
Anyview: Generalizable Indoor 3D Object Detection with Variable Frames
Oct 09, 2023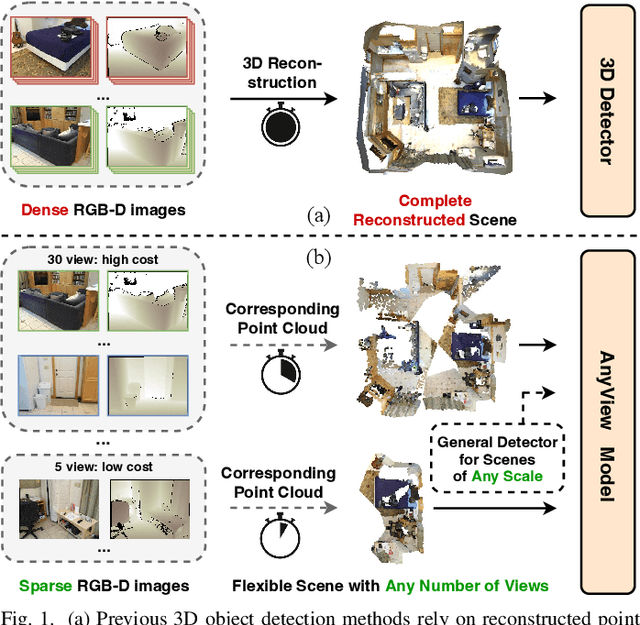
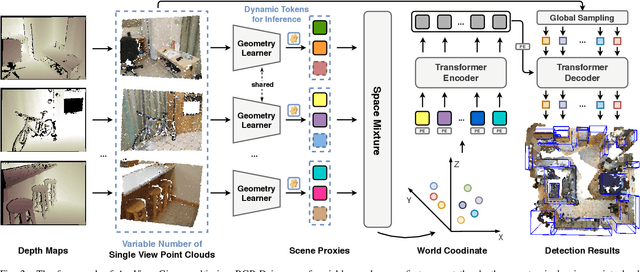

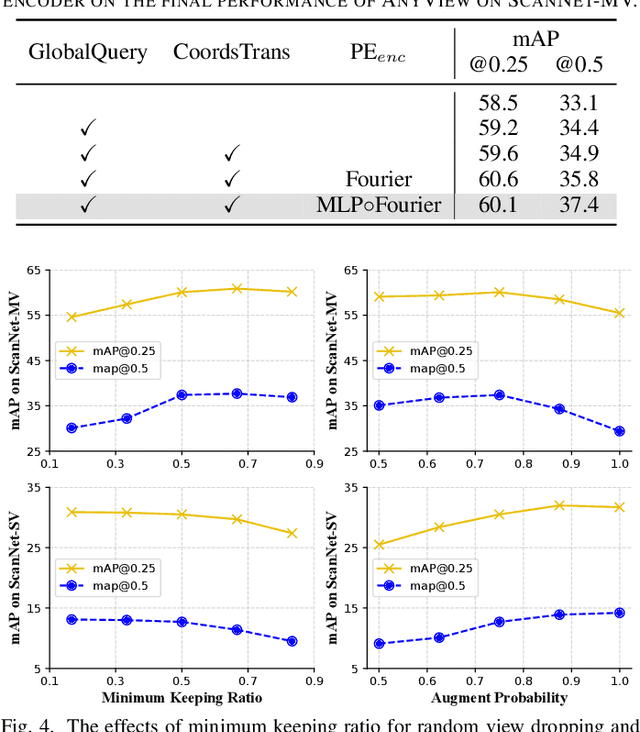
In this paper, we propose a novel network framework for indoor 3D object detection to handle variable input frame numbers in practical scenarios. Existing methods only consider fixed frames of input data for a single detector, such as monocular RGB-D images or point clouds reconstructed from dense multi-view RGB-D images. While in practical application scenes such as robot navigation and manipulation, the raw input to the 3D detectors is the RGB-D images with variable frame numbers instead of the reconstructed scene point cloud. However, the previous approaches can only handle fixed frame input data and have poor performance with variable frame input. In order to facilitate 3D object detection methods suitable for practical tasks, we present a novel 3D detection framework named AnyView for our practical applications, which generalizes well across different numbers of input frames with a single model. To be specific, we propose a geometric learner to mine the local geometric features of each input RGB-D image frame and implement local-global feature interaction through a designed spatial mixture module. Meanwhile, we further utilize a dynamic token strategy to adaptively adjust the number of extracted features for each frame, which ensures consistent global feature density and further enhances the generalization after fusion. Extensive experiments on the ScanNet dataset show our method achieves both great generalizability and high detection accuracy with a simple and clean architecture containing a similar amount of parameters with the baselines.
Dense Hybrid Proposal Modulation for Lane Detection
Apr 28, 2023In this paper, we present a dense hybrid proposal modulation (DHPM) method for lane detection. Most existing methods perform sparse supervision on a subset of high-scoring proposals, while other proposals fail to obtain effective shape and location guidance, resulting in poor overall quality. To address this, we densely modulate all proposals to generate topologically and spatially high-quality lane predictions with discriminative representations. Specifically, we first ensure that lane proposals are physically meaningful by applying single-lane shape and location constraints. Benefitting from the proposed proposal-to-label matching algorithm, we assign each proposal a target ground truth lane to efficiently learn from spatial layout priors. To enhance the generalization and model the inter-proposal relations, we diversify the shape difference of proposals matching the same ground-truth lane. In addition to the shape and location constraints, we design a quality-aware classification loss to adaptively supervise each positive proposal so that the discriminative power can be further boosted. Our DHPM achieves very competitive performances on four popular benchmark datasets. Moreover, we consistently outperform the baseline model on most metrics without introducing new parameters and reducing inference speed.
SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
Mar 16, 2023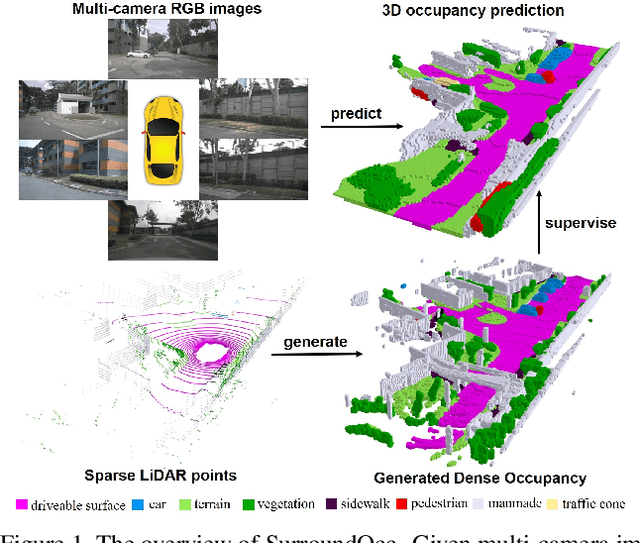
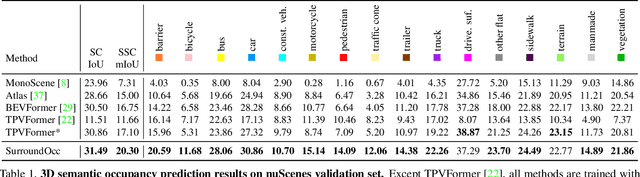
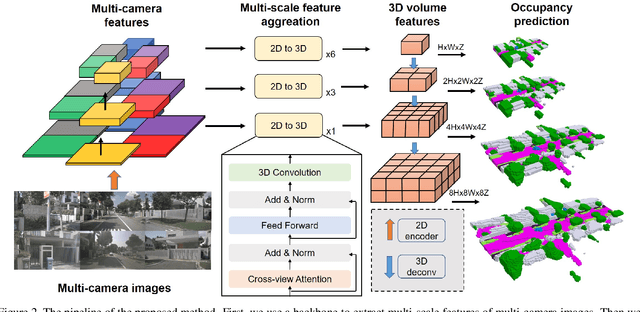

3D scene understanding plays a vital role in vision-based autonomous driving. While most existing methods focus on 3D object detection, they have difficulty describing real-world objects of arbitrary shapes and infinite classes. Towards a more comprehensive perception of a 3D scene, in this paper, we propose a SurroundOcc method to predict the 3D occupancy with multi-camera images. We first extract multi-scale features for each image and adopt spatial 2D-3D attention to lift them to the 3D volume space. Then we apply 3D convolutions to progressively upsample the volume features and impose supervision on multiple levels. To obtain dense occupancy prediction, we design a pipeline to generate dense occupancy ground truth without expansive occupancy annotations. Specifically, we fuse multi-frame LiDAR scans of dynamic objects and static scenes separately. Then we adopt Poisson Reconstruction to fill the holes and voxelize the mesh to get dense occupancy labels. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our method. Code and dataset are available at https://github.com/weiyithu/SurroundOcc
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Apr 07, 2022



Depth estimation from images serves as the fundamental step of 3D perception for autonomous driving and is an economical alternative to expensive depth sensors like LiDAR. The temporal photometric consistency enables self-supervised depth estimation without labels, further facilitating its application. However, most existing methods predict the depth solely based on each monocular image and ignore the correlations among multiple surrounding cameras, which are typically available for modern self-driving vehicles. In this paper, we propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. Specifically, we employ a joint network to process all the surrounding views and propose a cross-view transformer to effectively fuse the information from multiple views. We apply cross-view self-attention to efficiently enable the global interactions between multi-camera feature maps. Different from self-supervised monocular depth estimation, we are able to predict real-world scales given multi-camera extrinsic matrices. To achieve this goal, we adopt structure-from-motion to extract scale-aware pseudo depths to pretrain the models. Further, instead of predicting the ego-motion of each individual camera, we estimate a universal ego-motion of the vehicle and transfer it to each view to achieve multi-view consistency. In experiments, our method achieves the state-of-the-art performance on the challenging multi-camera depth estimation datasets DDAD and nuScenes.
Similarity-Aware Fusion Network for 3D Semantic Segmentation
Jul 17, 2021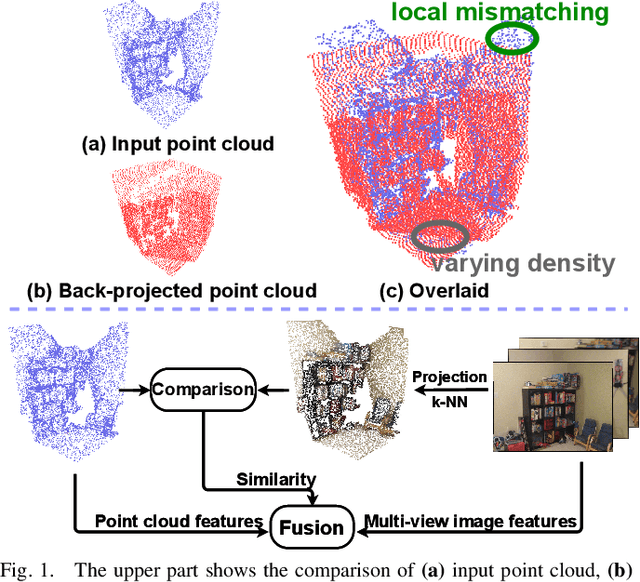
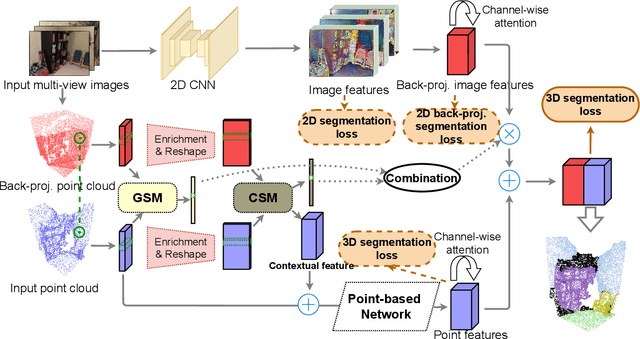
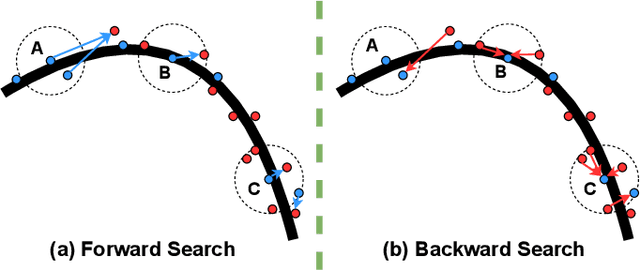
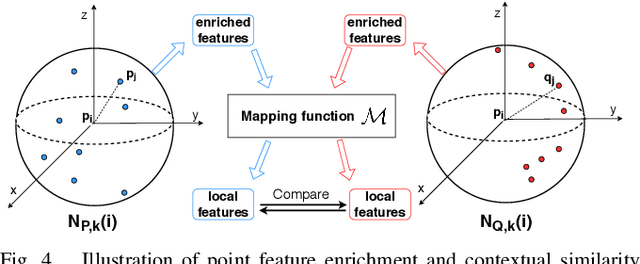
In this paper, we propose a similarity-aware fusion network (SAFNet) to adaptively fuse 2D images and 3D point clouds for 3D semantic segmentation. Existing fusion-based methods achieve remarkable performances by integrating information from multiple modalities. However, they heavily rely on the correspondence between 2D pixels and 3D points by projection and can only perform the information fusion in a fixed manner, and thus their performances cannot be easily migrated to a more realistic scenario where the collected data often lack strict pair-wise features for prediction. To address this, we employ a late fusion strategy where we first learn the geometric and contextual similarities between the input and back-projected (from 2D pixels) point clouds and utilize them to guide the fusion of two modalities to further exploit complementary information. Specifically, we employ a geometric similarity module (GSM) to directly compare the spatial coordinate distributions of pair-wise 3D neighborhoods, and a contextual similarity module (CSM) to aggregate and compare spatial contextual information of corresponding central points. The two proposed modules can effectively measure how much image features can help predictions, enabling the network to adaptively adjust the contributions of two modalities to the final prediction of each point. Experimental results on the ScanNetV2 benchmark demonstrate that SAFNet significantly outperforms existing state-of-the-art fusion-based approaches across various data integrity.