 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualization of Age Distributions as Elements of Medical Data-Stories
Sep 26, 2024



In various fields, including medicine, age distributions are crucial. Despite widespread media coverage of health topics, there remains a need to enhance health communication. Narrative medical visualization is promising for improving information comprehension and retention. This study explores the most effective ways to present age distributions of diseases through narrative visualizations. We conducted a thorough analysis of existing visualizations, held workshops with a broad audience, and reviewed relevant literature. From this, we identified design choices focusing on comprehension, aesthetics, engagement, and memorability. We specifically tested three pictogram variants: pictograms as bars, stacked pictograms, and annotations. After evaluating 18 visualizations with 72 participants and three expert reviews, we determined that annotations were most effective for comprehension and aesthetics. However, traditional bar charts were preferred for engagement, and other variants were more memorable. The study provides a set of design recommendations based on these insights.
Paparazzi: A Deep Dive into the Capabilities of Language and Vision Models for Grounding Viewpoint Descriptions
Feb 13, 2023



Existing language and vision models achieve impressive performance in image-text understanding. Yet, it is an open question to what extent they can be used for language understanding in 3D environments and whether they implicitly acquire 3D object knowledge, e.g. about different views of an object. In this paper, we investigate whether a state-of-the-art language and vision model, CLIP, is able to ground perspective descriptions of a 3D object and identify canonical views of common objects based on text queries. We present an evaluation framework that uses a circling camera around a 3D object to generate images from different viewpoints and evaluate them in terms of their similarity to natural language descriptions. We find that a pre-trained CLIP model performs poorly on most canonical views and that fine-tuning using hard negative sampling and random contrasting yields good results even under conditions with little available training data.
Cardiac Cohort Classification based on Morphologic and Hemodynamic Parameters extracted from 4D PC-MRI Data
Oct 12, 2020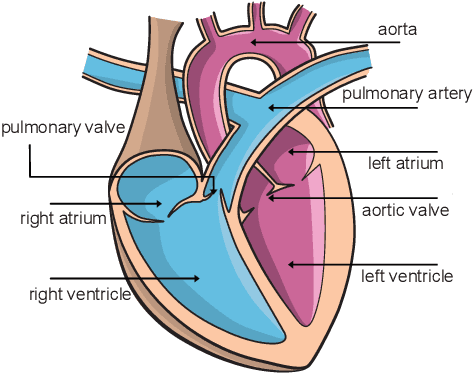

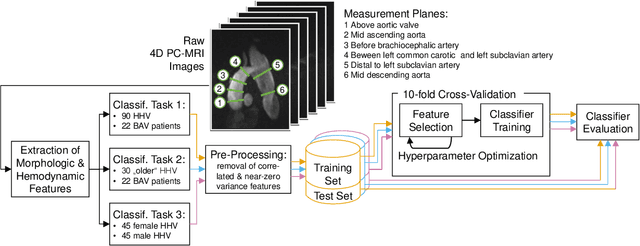

An accurate assessment of the cardiovascular system and prediction of cardiovascular diseases (CVDs) are crucial. Measured cardiac blood flow data provide insights about patient-specific hemodynamics, where many specialized techniques have been developed for the visual exploration of such data sets to better understand the influence of morphological and hemodynamic conditions on CVDs. However, there is a lack of machine learning approaches techniques that allow a feature-based classification of heart-healthy people and patients with CVDs.In this work, we investigate the potential of morphological and hemodynamic characteristics, extracted from measured blood flow data in the aorta, for the classification of heart-healthy volunteers and patients with bicuspid aortic valve (BAV). Furthermore, we research if there are characteristic features to classify male and female as well as younger and older heart-healthy volunteers. We propose a data analysis pipeline for the classification of the cardiac status, encompassing feature selection, model training and hyperparameter tuning. In our experiments, we use several feature selection methods and classification algorithms to train separate models for the healthy subgroups and BAV patients. We report on classification performance and investigate the predictive power of morphological and hemodynamic features with regard to the classification oft he defined groups. Finally, we identify the key features for the best models.