 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Subspace Generation for Outlier Detection in High-Dimensional Data
Apr 10, 2025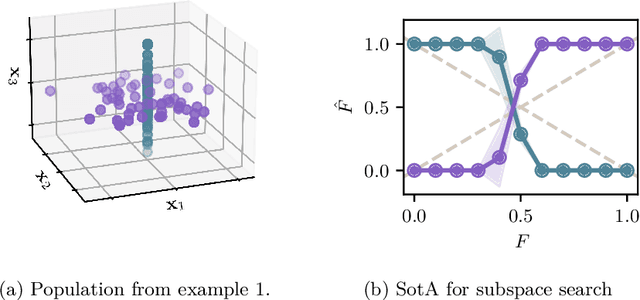

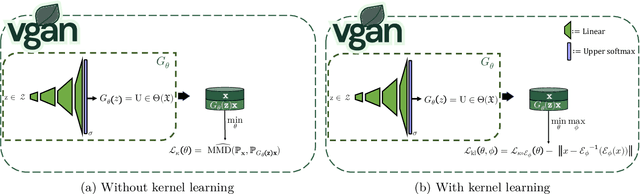

Outlier detection in high-dimensional tabular data is challenging since data is often distributed across multiple lower-dimensional subspaces -- a phenomenon known as the Multiple Views effect (MV). This effect led to a large body of research focused on mining such subspaces, known as subspace selection. However, as the precise nature of the MV effect was not well understood, traditional methods had to rely on heuristic-driven search schemes that struggle to accurately capture the true structure of the data. Properly identifying these subspaces is critical for unsupervised tasks such as outlier detection or clustering, where misrepresenting the underlying data structure can hinder the performance. We introduce Myopic Subspace Theory (MST), a new theoretical framework that mathematically formulates the Multiple Views effect and writes subspace selection as a stochastic optimization problem. Based on MST, we introduce V-GAN, a generative method trained to solve such an optimization problem. This approach avoids any exhaustive search over the feature space while ensuring that the intrinsic data structure is preserved. Experiments on 42 real-world datasets show that using V-GAN subspaces to build ensemble methods leads to a significant increase in one-class classification performance -- compared to existing subspace selection, feature selection, and embedding methods. Further experiments on synthetic data show that V-GAN identifies subspaces more accurately while scaling better than other relevant subspace selection methods. These results confirm the theoretical guarantees of our approach and also highlight its practical viability in high-dimensional settings.
Generalizability of experimental studies
Jun 25, 2024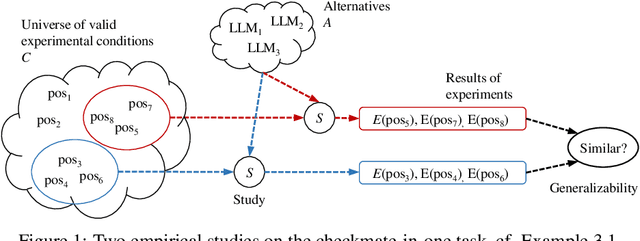
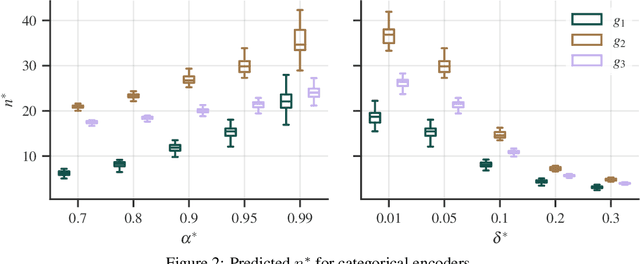
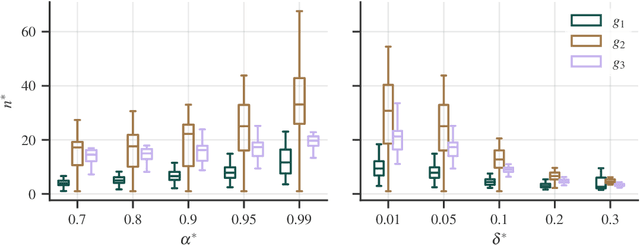
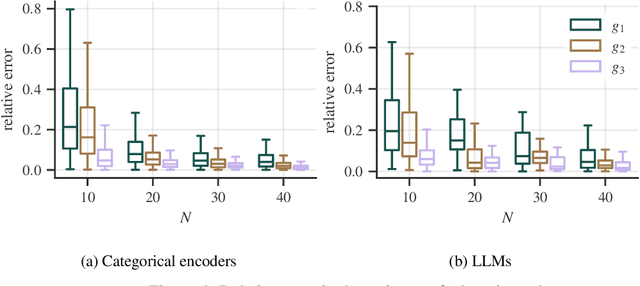
Experimental studies are a cornerstone of machine learning (ML) research. A common, but often implicit, assumption is that the results of a study will generalize beyond the study itself, e.g. to new data. That is, there is a high probability that repeating the study under different conditions will yield similar results. Despite the importance of the concept, the problem of measuring generalizability remains open. This is probably due to the lack of a mathematical formalization of experimental studies. In this paper, we propose such a formalization and develop a quantifiable notion of generalizability. This notion allows to explore the generalizability of existing studies and to estimate the number of experiments needed to achieve the generalizability of new studies. To demonstrate its usefulness, we apply it to two recently published benchmarks to discern generalizable and non-generalizable results. We also publish a Python module that allows our analysis to be repeated for other experimental studies.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
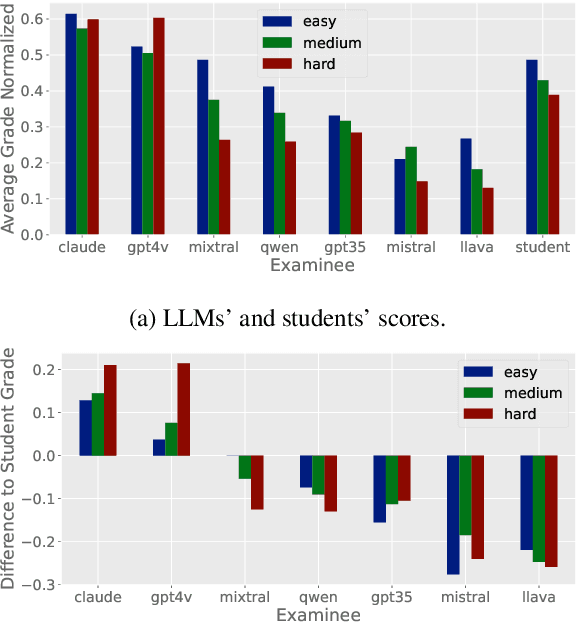

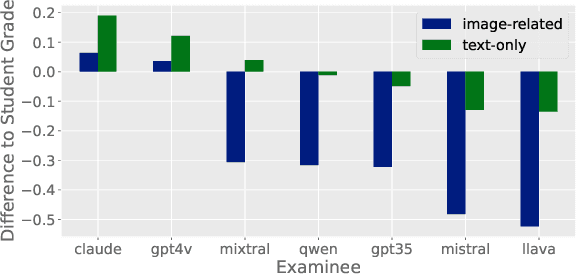
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
Generative Subspace Adversarial Active Learning for Outlier Detection in Multiple Views of High-dimensional Data
Apr 20, 2024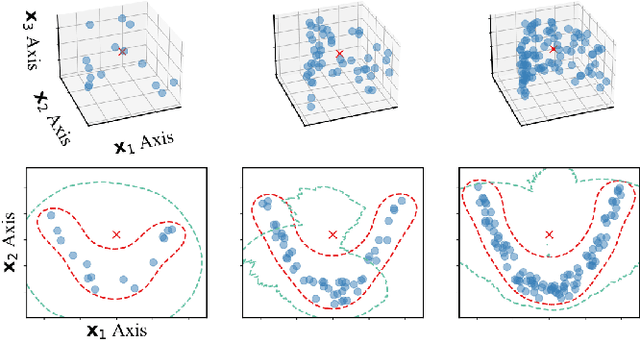

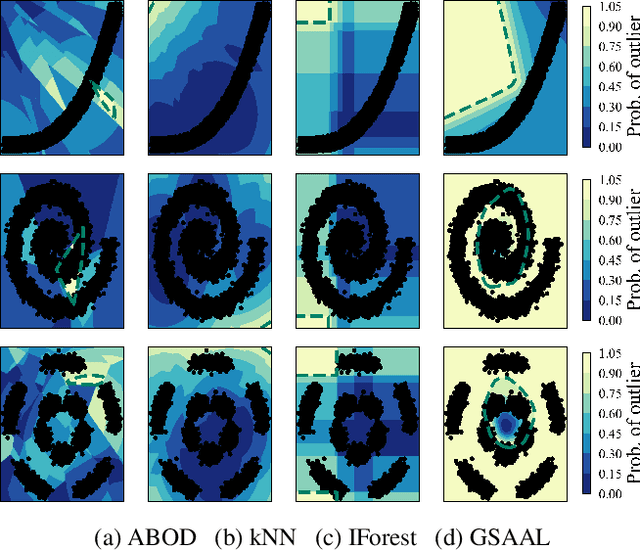
Outlier detection in high-dimensional tabular data is an important task in data mining, essential for many downstream tasks and applications. Existing unsupervised outlier detection algorithms face one or more problems, including inlier assumption (IA), curse of dimensionality (CD), and multiple views (MV). To address these issues, we introduce Generative Subspace Adversarial Active Learning (GSAAL), a novel approach that uses a Generative Adversarial Network with multiple adversaries. These adversaries learn the marginal class probability functions over different data subspaces, while a single generator in the full space models the entire distribution of the inlier class. GSAAL is specifically designed to address the MV limitation while also handling the IA and CD, being the only method to do so. We provide a comprehensive mathematical formulation of MV, convergence guarantees for the discriminators, and scalability results for GSAAL. Our extensive experiments demonstrate the effectiveness and scalability of GSAAL, highlighting its superior performance compared to other popular OD methods, especially in MV scenarios.
Efficient Generation of Hidden Outliers for Improved Outlier Detection
Feb 06, 2024



Outlier generation is a popular technique used for solving important outlier detection tasks. Generating outliers with realistic behavior is challenging. Popular existing methods tend to disregard the 'multiple views' property of outliers in high-dimensional spaces. The only existing method accounting for this property falls short in efficiency and effectiveness. We propose BISECT, a new outlier generation method that creates realistic outliers mimicking said property. To do so, BISECT employs a novel proposition introduced in this article stating how to efficiently generate said realistic outliers. Our method has better guarantees and complexity than the current methodology for recreating 'multiple views'. We use the synthetic outliers generated by BISECT to effectively enhance outlier detection in diverse datasets, for multiple use cases. For instance, oversampling with BISECT reduced the error by up to 3 times when compared with the baselines.
Uncertainty-Aware Partial-Label Learning
Feb 01, 2024


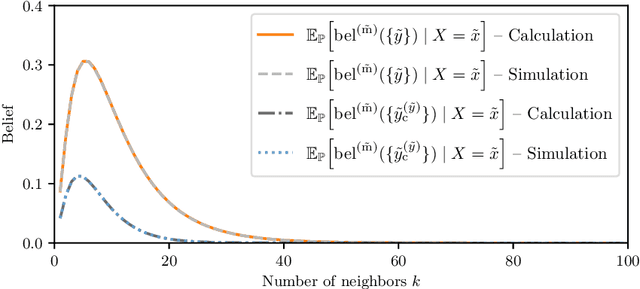
In real-world applications, one often encounters ambiguously labeled data, where different annotators assign conflicting class labels. Partial-label learning allows training classifiers in this weakly supervised setting. While state-of-the-art methods already feature good predictive performance, they often suffer from miscalibrated uncertainty estimates. However, having well-calibrated uncertainty estimates is important, especially in safety-critical domains like medicine and autonomous driving. In this article, we propose a novel nearest-neighbor-based partial-label-learning algorithm that leverages Dempster-Shafer theory. Extensive experiments on artificial and real-world datasets show that the proposed method provides a well-calibrated uncertainty estimate and achieves competitive prediction performance. Additionally, we prove that our algorithm is risk-consistent.
Adaptive Bernstein Change Detector for High-Dimensional Data Streams
Jun 22, 2023
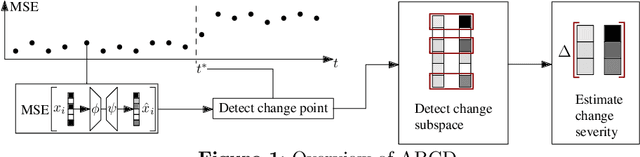


Change detection is of fundamental importance when analyzing data streams. Detecting changes both quickly and accurately enables monitoring and prediction systems to react, e.g., by issuing an alarm or by updating a learning algorithm. However, detecting changes is challenging when observations are high-dimensional. In high-dimensional data, change detectors should not only be able to identify when changes happen, but also in which subspace they occur. Ideally, one should also quantify how severe they are. Our approach, ABCD, has these properties. ABCD learns an encoder-decoder model and monitors its accuracy over a window of adaptive size. ABCD derives a change score based on Bernstein's inequality to detect deviations in terms of accuracy, which indicate changes. Our experiments demonstrate that ABCD outperforms its best competitor by at least 8% and up to 23% in F1-score on average. It can also accurately estimate changes' subspace, together with a severity measure that correlates with the ground truth.
Budgeted Multi-Armed Bandits with Asymmetric Confidence Intervals
Jun 12, 2023We study the stochastic Budgeted Multi-Armed Bandit (MAB) problem, where a player chooses from $K$ arms with unknown expected rewards and costs. The goal is to maximize the total reward under a budget constraint. A player thus seeks to choose the arm with the highest reward-cost ratio as often as possible. Current state-of-the-art policies for this problem have several issues, which we illustrate. To overcome them, we propose a new upper confidence bound (UCB) sampling policy, $\omega$-UCB, that uses asymmetric confidence intervals. These intervals scale with the distance between the sample mean and the bounds of a random variable, yielding a more accurate and tight estimation of the reward-cost ratio compared to our competitors. We show that our approach has logarithmic regret and consistently outperforms existing policies in synthetic and real settings.
Scalable Online Change Detection for High-dimensional Data Streams
May 25, 2022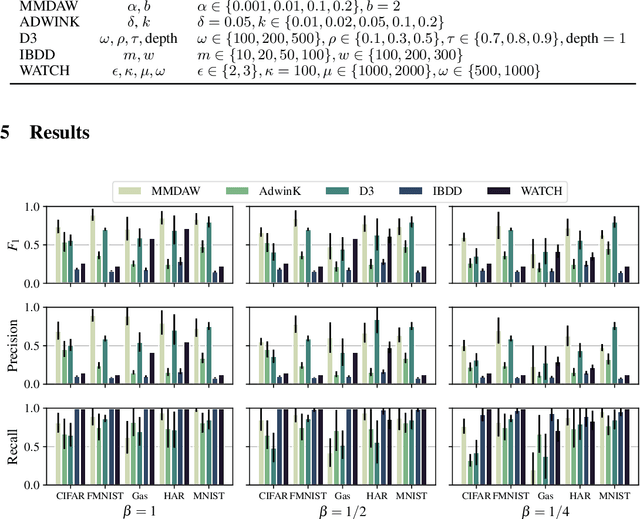

Detecting changes in data streams is a core objective in their analysis and has applications in, say, predictive maintenance, fraud detection, and medicine. A principled approach to detect changes is to compare distributions observed within the stream to each other. However, data streams often are high-dimensional, and changes can be complex, e.g., only manifest themselves in higher moments. The streaming setting also imposes heavy memory and computation restrictions. We propose an algorithm, Maximum Mean Discrepancy Adaptive Windowing (MMDAW), which leverages the well-known Maximum Mean Discrepancy (MMD) two-sample test, and facilitates its efficient online computation on windows whose size it flexibly adapts. As MMD is sensitive to any change in the underlying distribution, our algorithm is a general-purpose non-parametric change detector that fulfills the requirements imposed by the streaming setting. Our experiments show that MMDAW achieves better detection quality than state-of-the-art competitors.
Pedagogical Rule Extraction for Learning Interpretable Models
Dec 25, 2021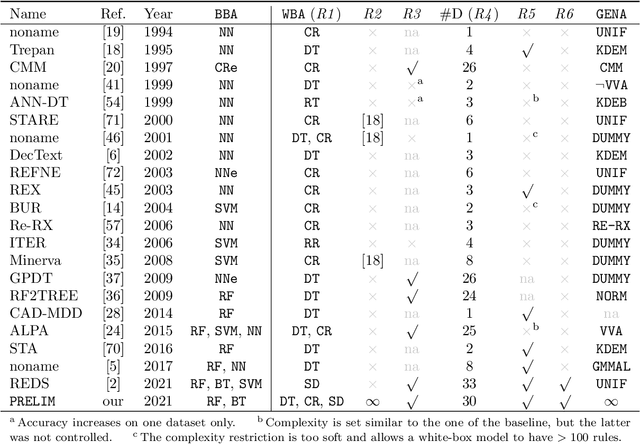
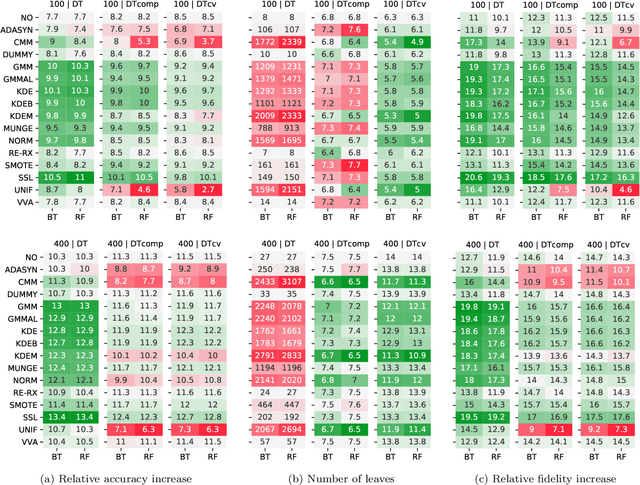
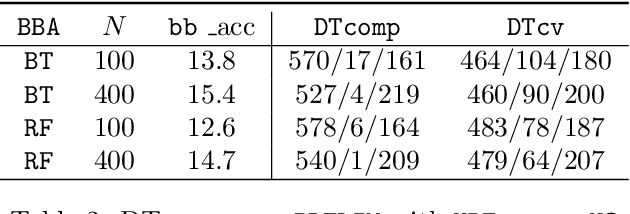
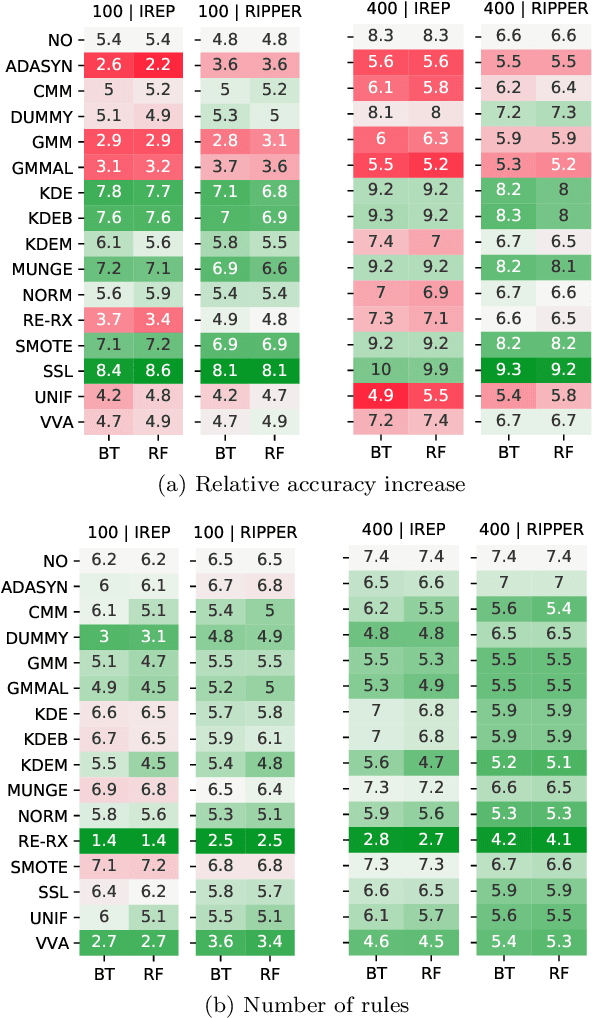
Machine-learning models are ubiquitous. In some domains, for instance, in medicine, the models' predictions must be interpretable. Decision trees, classification rules, and subgroup discovery are three broad categories of supervised machine-learning models presenting knowledge in the form of interpretable rules. The accuracy of these models learned from small datasets is usually low. Obtaining larger datasets is often hard to impossible. We propose a framework dubbed PRELIM to learn better rules from small data. It augments data using statistical models and employs it to learn a rulebased model. In our extensive experiments, we identified PRELIM configurations that outperform state-of-the-art.