 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Partial-Label Learning by Leveraging Class Activation Values
Feb 17, 2025


Real-world training data is often noisy; for example, human annotators assign conflicting class labels to the same instances. Partial-label learning (PLL) is a weakly supervised learning paradigm that allows training classifiers in this context without manual data cleaning. While state-of-the-art methods have good predictive performance, their predictions are sensitive to high noise levels, out-of-distribution data, and adversarial perturbations. We propose a novel PLL method based on subjective logic, which explicitly represents uncertainty by leveraging the magnitudes of the underlying neural network's class activation values. Thereby, we effectively incorporate prior knowledge about the class labels by using a novel label weight re-distribution strategy that we prove to be optimal. We empirically show that our method yields more robust predictions in terms of predictive performance under high PLL noise levels, handling out-of-distribution examples, and handling adversarial perturbations on the test instances.
Partial-Label Learning with Conformal Candidate Cleaning
Feb 11, 2025Real-world data is often ambiguous; for example, human annotation produces instances with multiple conflicting class labels. Partial-label learning (PLL) aims at training a classifier in this challenging setting, where each instance is associated with a set of candidate labels and one correct, but unknown, class label. A multitude of algorithms targeting this setting exists and, to enhance their prediction quality, several extensions that are applicable across a wide range of PLL methods have been introduced. While many of these extensions rely on heuristics, this article proposes a novel enhancing method that incrementally prunes candidate sets using conformal prediction. To work around the missing labeled validation set, which is typically required for conformal prediction, we propose a strategy that alternates between training a PLL classifier to label the validation set, leveraging these predicted class labels for calibration, and pruning candidate labels that are not part of the resulting conformal sets. In this sense, our method alternates between empirical risk minimization and candidate set pruning. We establish that our pruning method preserves the conformal validity with respect to the unknown ground truth. Our extensive experiments on artificial and real-world data show that the proposed approach significantly improves the test set accuracies of several state-of-the-art PLL classifiers.
Milling using two mechatronically coupled robots
Apr 17, 2024Industrial robots are commonly used in various industries due to their flexibility. However, their adoption for machining tasks is minimal because of the low dynamic stiffness characteristic of serial kinematic chains. To overcome this problem, we propose coupling two industrial robots at the flanges to form a parallel kinematic machining system. Although parallel kinematic chains are inherently stiffer, one possible disadvantage of the proposed system is that it is heavily overactuated. We perform a modal analysis to show that this may be an advantage, as the redundant degrees of freedom can be used to shift the natural frequencies by applying tension to the coupling module. To demonstrate the validity of our approach, we perform a milling experiment using our coupled system. An external measurement system is used to show that tensioning the coupling module causes a deformation of the system. We further show that this deformation is static over the tool path and can be compensated for.
Uncertainty-Aware Partial-Label Learning
Feb 01, 2024


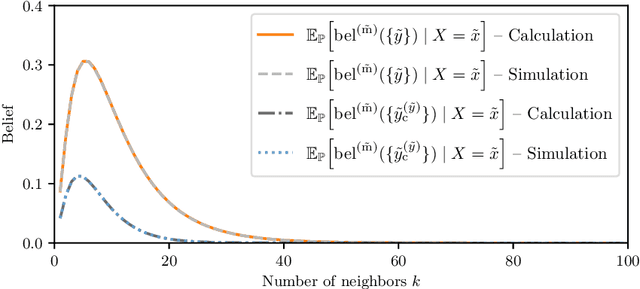
In real-world applications, one often encounters ambiguously labeled data, where different annotators assign conflicting class labels. Partial-label learning allows training classifiers in this weakly supervised setting. While state-of-the-art methods already feature good predictive performance, they often suffer from miscalibrated uncertainty estimates. However, having well-calibrated uncertainty estimates is important, especially in safety-critical domains like medicine and autonomous driving. In this article, we propose a novel nearest-neighbor-based partial-label-learning algorithm that leverages Dempster-Shafer theory. Extensive experiments on artificial and real-world datasets show that the proposed method provides a well-calibrated uncertainty estimate and achieves competitive prediction performance. Additionally, we prove that our algorithm is risk-consistent.