 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Subspace Generation for Outlier Detection in High-Dimensional Data
Apr 10, 2025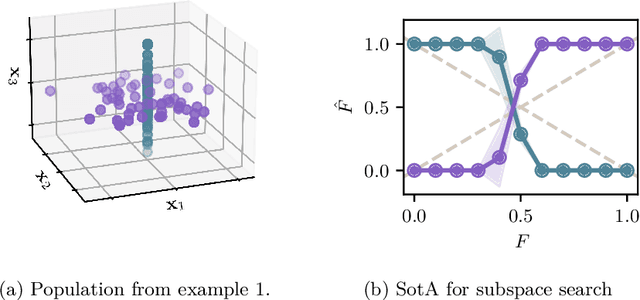

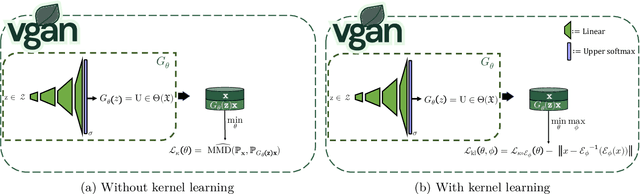

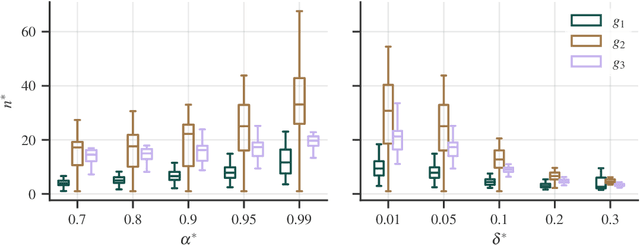
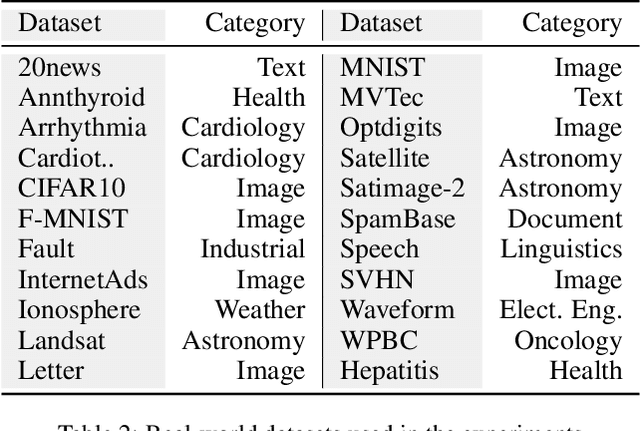
Outlier detection in high-dimensional tabular data is challenging since data is often distributed across multiple lower-dimensional subspaces -- a phenomenon known as the Multiple Views effect (MV). This effect led to a large body of research focused on mining such subspaces, known as subspace selection. However, as the precise nature of the MV effect was not well understood, traditional methods had to rely on heuristic-driven search schemes that struggle to accurately capture the true structure of the data. Properly identifying these subspaces is critical for unsupervised tasks such as outlier detection or clustering, where misrepresenting the underlying data structure can hinder the performance. We introduce Myopic Subspace Theory (MST), a new theoretical framework that mathematically formulates the Multiple Views effect and writes subspace selection as a stochastic optimization problem. Based on MST, we introduce V-GAN, a generative method trained to solve such an optimization problem. This approach avoids any exhaustive search over the feature space while ensuring that the intrinsic data structure is preserved. Experiments on 42 real-world datasets show that using V-GAN subspaces to build ensemble methods leads to a significant increase in one-class classification performance -- compared to existing subspace selection, feature selection, and embedding methods. Further experiments on synthetic data show that V-GAN identifies subspaces more accurately while scaling better than other relevant subspace selection methods. These results confirm the theoretical guarantees of our approach and also highlight its practical viability in high-dimensional settings.
Generalizability of experimental studies
Jun 25, 2024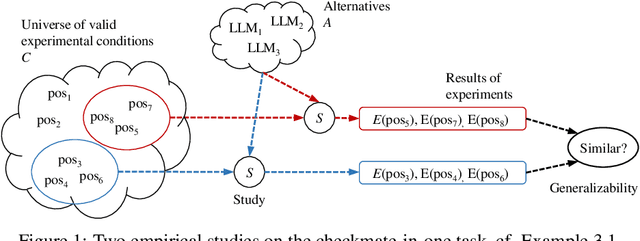
Experimental studies are a cornerstone of machine learning (ML) research. A common, but often implicit, assumption is that the results of a study will generalize beyond the study itself, e.g. to new data. That is, there is a high probability that repeating the study under different conditions will yield similar results. Despite the importance of the concept, the problem of measuring generalizability remains open. This is probably due to the lack of a mathematical formalization of experimental studies. In this paper, we propose such a formalization and develop a quantifiable notion of generalizability. This notion allows to explore the generalizability of existing studies and to estimate the number of experiments needed to achieve the generalizability of new studies. To demonstrate its usefulness, we apply it to two recently published benchmarks to discern generalizable and non-generalizable results. We also publish a Python module that allows our analysis to be repeated for other experimental studies.
Generative Subspace Adversarial Active Learning for Outlier Detection in Multiple Views of High-dimensional Data
Apr 20, 2024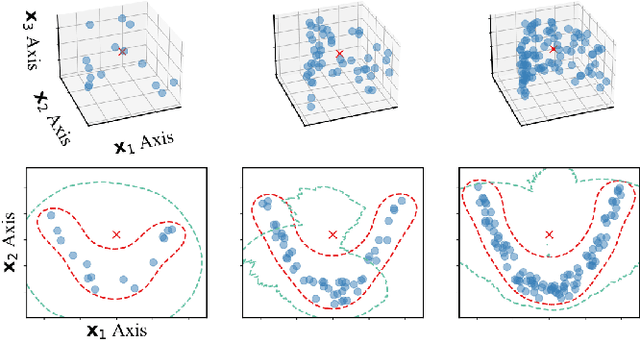

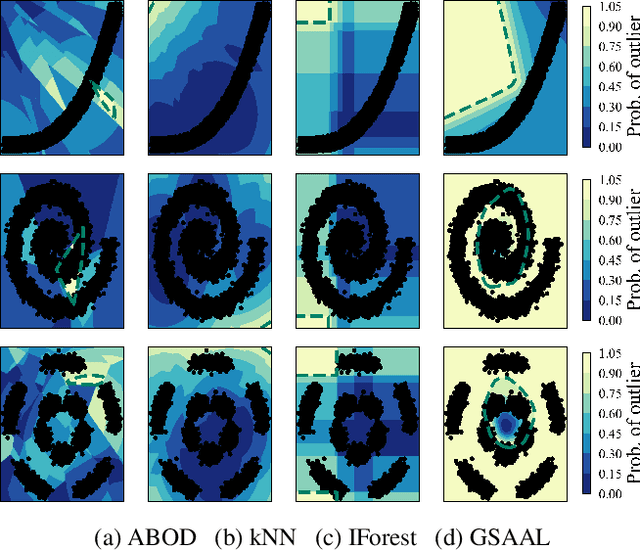
Outlier detection in high-dimensional tabular data is an important task in data mining, essential for many downstream tasks and applications. Existing unsupervised outlier detection algorithms face one or more problems, including inlier assumption (IA), curse of dimensionality (CD), and multiple views (MV). To address these issues, we introduce Generative Subspace Adversarial Active Learning (GSAAL), a novel approach that uses a Generative Adversarial Network with multiple adversaries. These adversaries learn the marginal class probability functions over different data subspaces, while a single generator in the full space models the entire distribution of the inlier class. GSAAL is specifically designed to address the MV limitation while also handling the IA and CD, being the only method to do so. We provide a comprehensive mathematical formulation of MV, convergence guarantees for the discriminators, and scalability results for GSAAL. Our extensive experiments demonstrate the effectiveness and scalability of GSAAL, highlighting its superior performance compared to other popular OD methods, especially in MV scenarios.
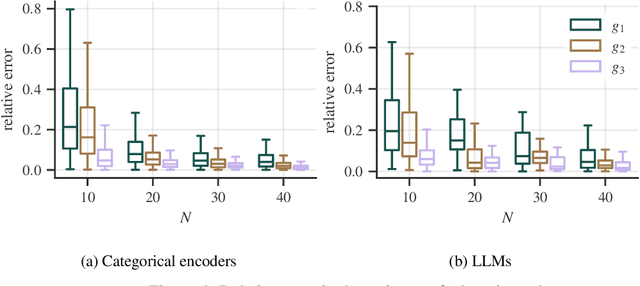
A benchmark of categorical encoders for binary classification
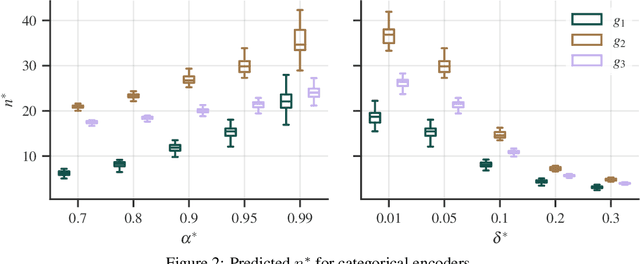
Jul 19, 2023Categorical encoders transform categorical features into numerical representations that are indispensable for a wide range of machine learning models. Existing encoder benchmark studies lack generalizability because of their limited choice of (1) encoders, (2) experimental factors, and (3) datasets. Additionally, inconsistencies arise from the adoption of varying aggregation strategies. This paper is the most comprehensive benchmark of categorical encoders to date, including an extensive evaluation of 32 configurations of encoders from diverse families, with 36 combinations of experimental factors, and on 50 datasets. The study shows the profound influence of dataset selection, experimental factors, and aggregation strategies on the benchmark's conclusions -- aspects disregarded in previous encoder benchmarks.