Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedagogical Rule Extraction for Learning Interpretable Models
Paper and Code
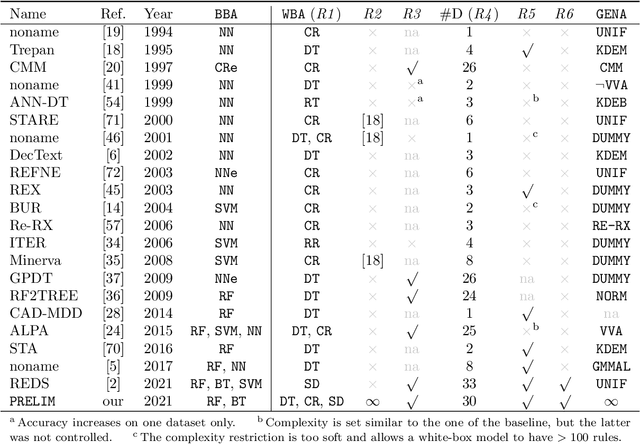
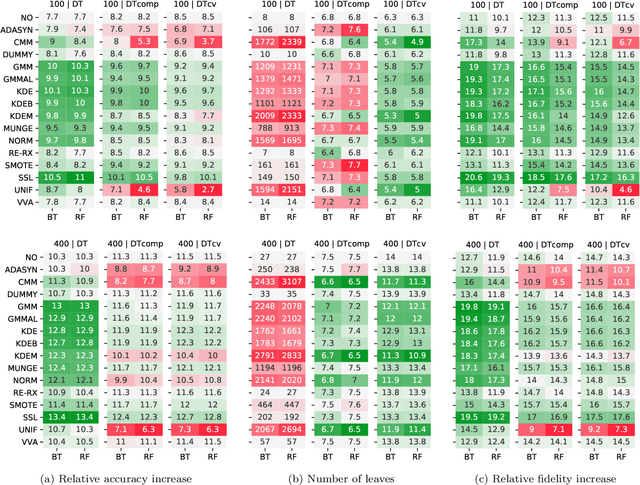
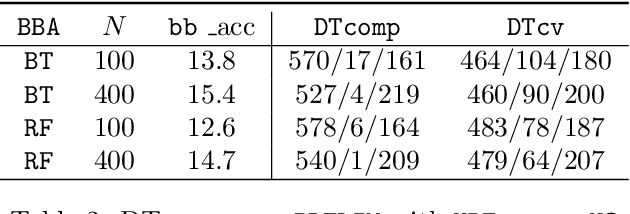
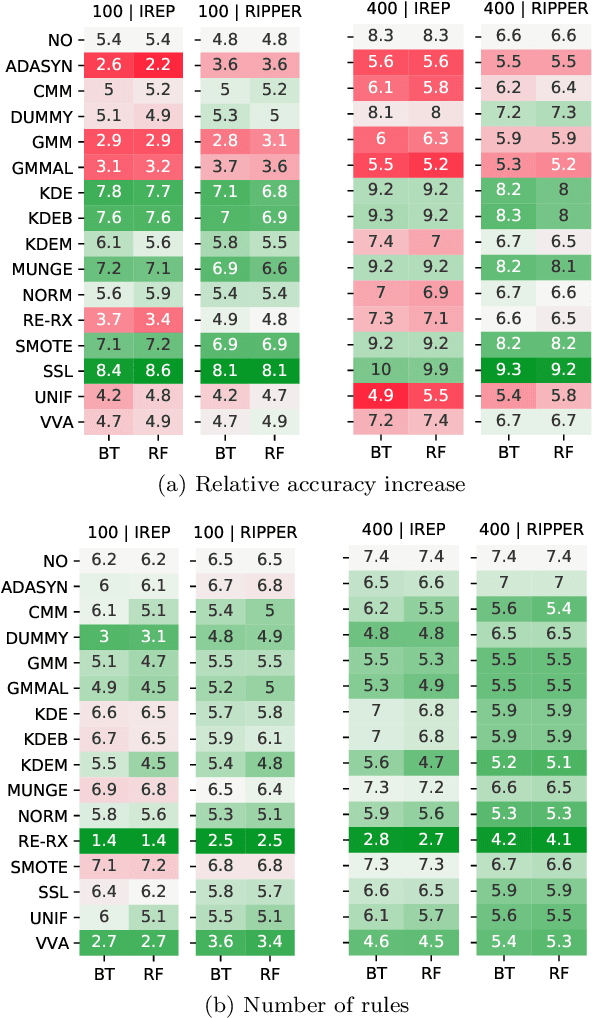
Machine-learning models are ubiquitous. In some domains, for instance, in medicine, the models' predictions must be interpretable. Decision trees, classification rules, and subgroup discovery are three broad categories of supervised machine-learning models presenting knowledge in the form of interpretable rules. The accuracy of these models learned from small datasets is usually low. Obtaining larger datasets is often hard to impossible. We propose a framework dubbed PRELIM to learn better rules from small data. It augments data using statistical models and employs it to learn a rulebased model. In our extensive experiments, we identified PRELIM configurations that outperform state-of-the-art.
View paper on