 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Cost Types, Interaction Schemes, and Annotator Performance Models in Selection Algorithms for Active Learning in Classification
Sep 23, 2021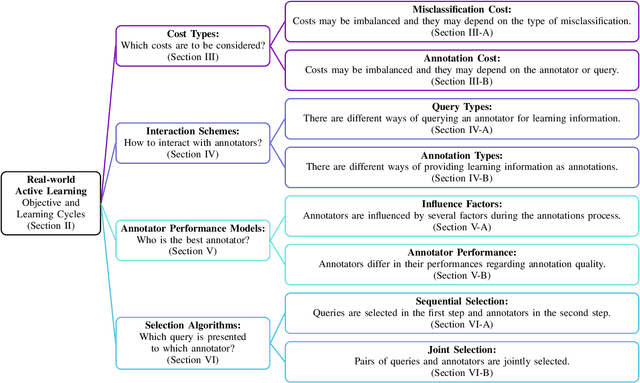
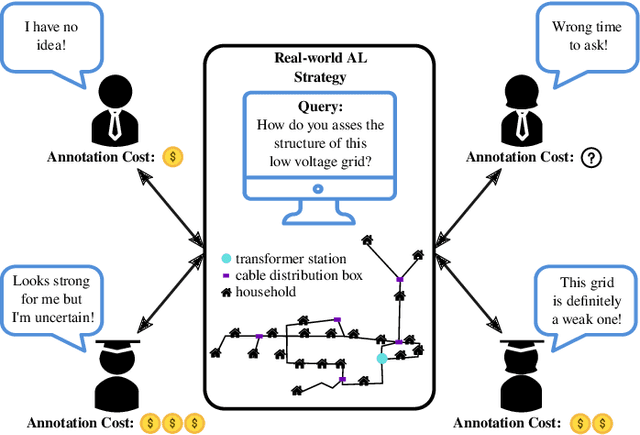
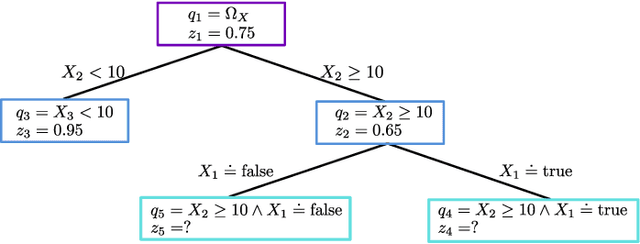
Pool-based active learning (AL) aims to optimize the annotation process (i.e., labeling) as the acquisition of annotations is often time-consuming and therefore expensive. For this purpose, an AL strategy queries annotations intelligently from annotators to train a high-performance classification model at a low annotation cost. Traditional AL strategies operate in an idealized framework. They assume a single, omniscient annotator who never gets tired and charges uniformly regardless of query difficulty. However, in real-world applications, we often face human annotators, e.g., crowd or in-house workers, who make annotation mistakes and can be reluctant to respond if tired or faced with complex queries. Recently, a wide range of novel AL strategies has been proposed to address these issues. They differ in at least one of the following three central aspects from traditional AL: (1) They explicitly consider (multiple) human annotators whose performances can be affected by various factors, such as missing expertise. (2) They generalize the interaction with human annotators by considering different query and annotation types, such as asking an annotator for feedback on an inferred classification rule. (3) They take more complex cost schemes regarding annotations and misclassifications into account. This survey provides an overview of these AL strategies and refers to them as real-world AL. Therefore, we introduce a general real-world AL strategy as part of a learning cycle and use its elements, e.g., the query and annotator selection algorithm, to categorize about 60 real-world AL strategies. Finally, we outline possible directions for future research in the field of AL.
The future of human-AI collaboration: a taxonomy of design knowledge for hybrid intelligence systems
May 07, 2021
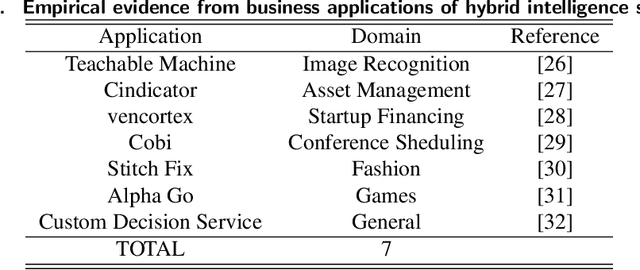
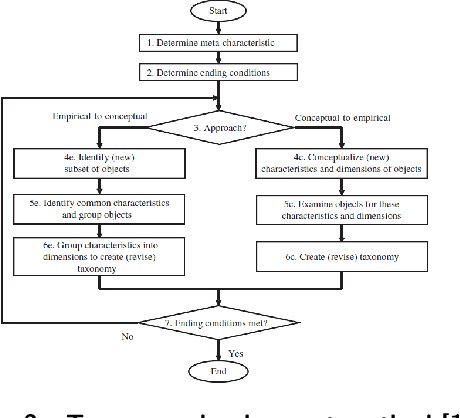
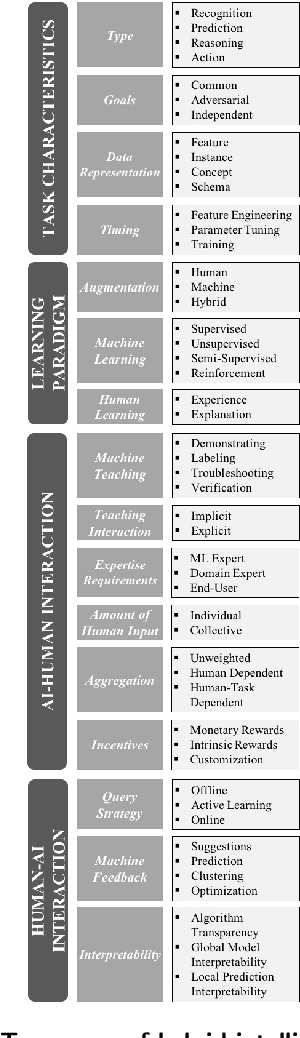
Recent technological advances, especially in the field of machine learning, provide astonishing progress on the road towards artificial general intelligence. However, tasks in current real-world business applications cannot yet be solved by machines alone. We, therefore, identify the need for developing socio-technological ensembles of humans and machines. Such systems possess the ability to accomplish complex goals by combining human and artificial intelligence to collectively achieve superior results and continuously improve by learning from each other. Thus, the need for structured design knowledge for those systems arises. Following a taxonomy development method, this article provides three main contributions: First, we present a structured overview of interdisciplinary research on the role of humans in the machine learning pipeline. Second, we envision hybrid intelligence systems and conceptualize the relevant dimensions for system design for the first time. Finally, we offer useful guidance for system developers during the implementation of such applications.
Semi-Supervised Active Learning for Support Vector Machines: A Novel Approach that Exploits Structure Information in Data
Oct 14, 2016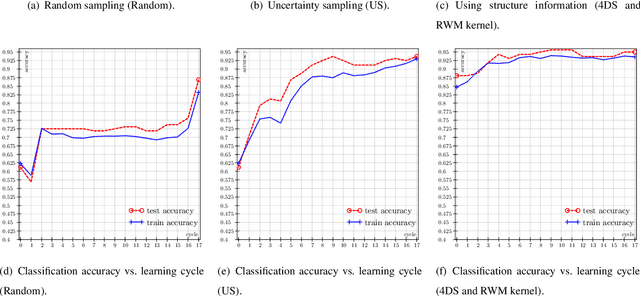
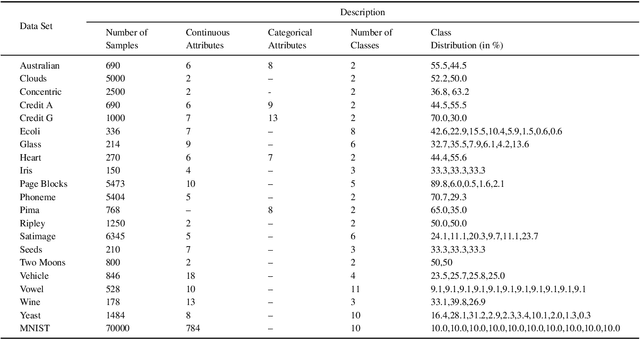

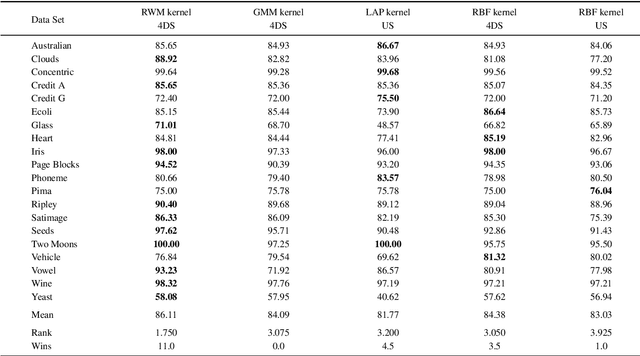
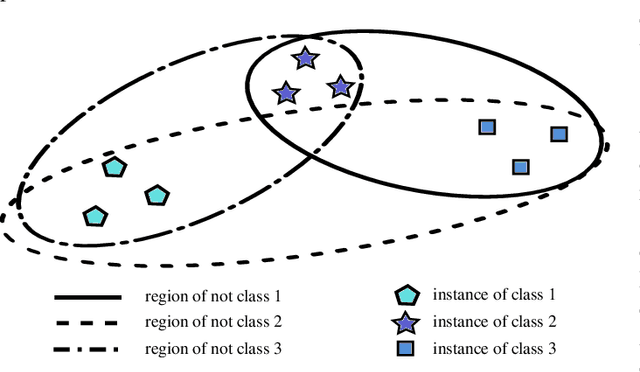
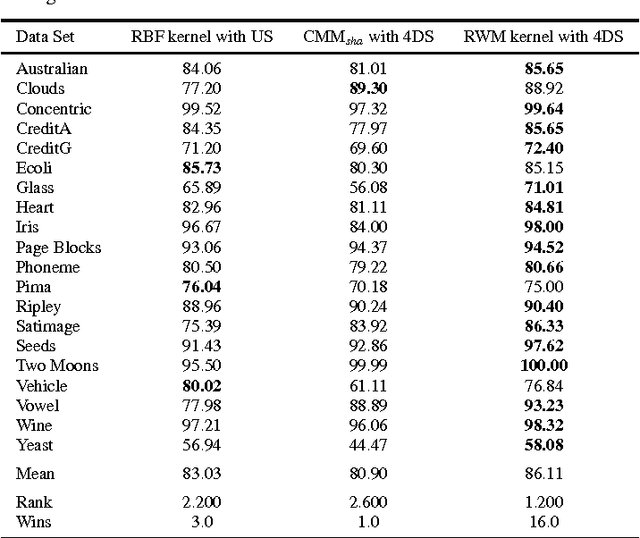
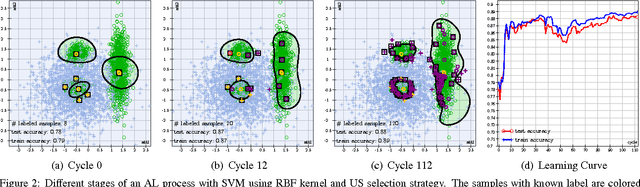
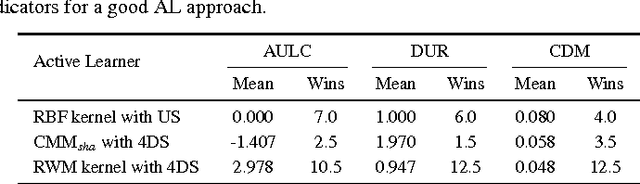
In our today's information society more and more data emerges, e.g.~in social networks, technical applications, or business applications. Companies try to commercialize these data using data mining or machine learning methods. For this purpose, the data are categorized or classified, but often at high (monetary or temporal) costs. An effective approach to reduce these costs is to apply any kind of active learning (AL) methods, as AL controls the training process of a classifier by specific querying individual data points (samples), which are then labeled (e.g., provided with class memberships) by a domain expert. However, an analysis of current AL research shows that AL still has some shortcomings. In particular, the structure information given by the spatial pattern of the (un)labeled data in the input space of a classification model (e.g.,~cluster information), is used in an insufficient way. In addition, many existing AL techniques pay too little attention to their practical applicability. To meet these challenges, this article presents several techniques that together build a new approach for combining AL and semi-supervised learning (SSL) for support vector machines (SVM) in classification tasks. Structure information is captured by means of probabilistic models that are iteratively improved at runtime when label information becomes available. The probabilistic models are considered in a selection strategy based on distance, density, diversity, and distribution (4DS strategy) information for AL and in a kernel function (Responsibility Weighted Mahalanobis kernel) for SVM. The approach fuses generative and discriminative modeling techniques. With 20 benchmark data sets and with the MNIST data set it is shown that our new solution yields significantly better results than state-of-the-art methods.
A New Vision of Collaborative Active Learning
Dec 22, 2015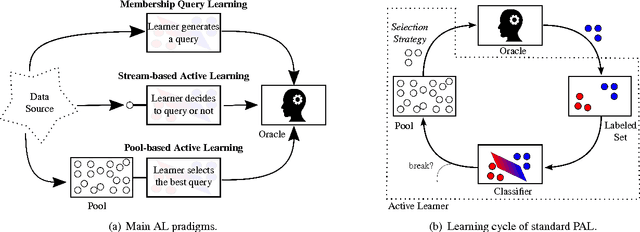
Active learning (AL) is a learning paradigm where an active learner has to train a model (e.g., a classifier) which is in principal trained in a supervised way, but in AL it has to be done by means of a data set with initially unlabeled samples. To get labels for these samples, the active learner has to ask an oracle (e.g., a human expert) for labels. The goal is to maximize the performance of the model and to minimize the number of queries at the same time. In this article, we first briefly discuss the state of the art and own, preliminary work in the field of AL. Then, we propose the concept of collaborative active learning (CAL). With CAL, we will overcome some of the harsh limitations of current AL. In particular, we envision scenarios where an expert may be wrong for various reasons, there might be several or even many experts with different expertise, the experts may label not only samples but also knowledge at a higher level such as rules, and we consider that the labeling costs depend on many conditions. Moreover, in a CAL process human experts will profit by improving their own knowledge, too.