 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Active Learning for Support Vector Machines: A Novel Approach that Exploits Structure Information in Data
Paper and Code
Oct 14, 2016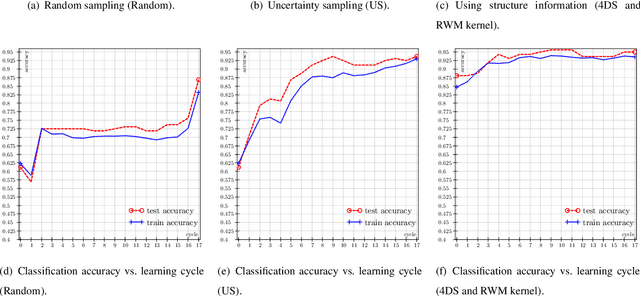
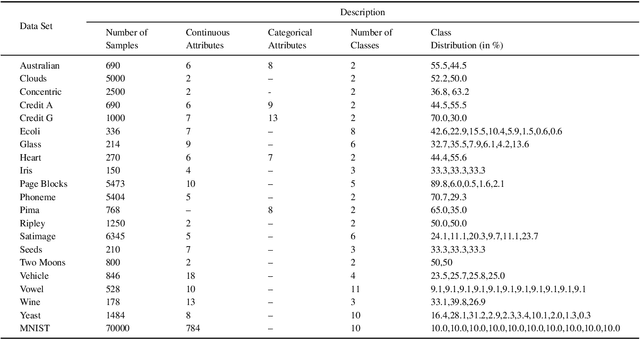

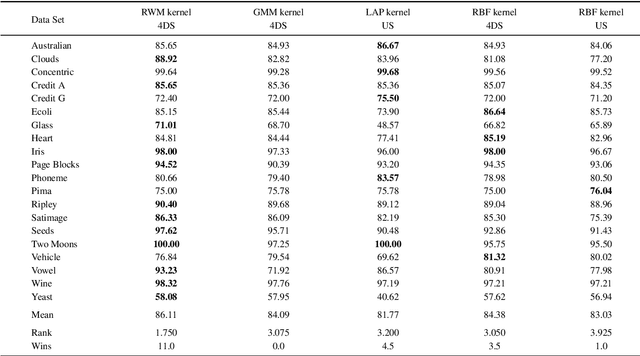
In our today's information society more and more data emerges, e.g.~in social networks, technical applications, or business applications. Companies try to commercialize these data using data mining or machine learning methods. For this purpose, the data are categorized or classified, but often at high (monetary or temporal) costs. An effective approach to reduce these costs is to apply any kind of active learning (AL) methods, as AL controls the training process of a classifier by specific querying individual data points (samples), which are then labeled (e.g., provided with class memberships) by a domain expert. However, an analysis of current AL research shows that AL still has some shortcomings. In particular, the structure information given by the spatial pattern of the (un)labeled data in the input space of a classification model (e.g.,~cluster information), is used in an insufficient way. In addition, many existing AL techniques pay too little attention to their practical applicability. To meet these challenges, this article presents several techniques that together build a new approach for combining AL and semi-supervised learning (SSL) for support vector machines (SVM) in classification tasks. Structure information is captured by means of probabilistic models that are iteratively improved at runtime when label information becomes available. The probabilistic models are considered in a selection strategy based on distance, density, diversity, and distribution (4DS strategy) information for AL and in a kernel function (Responsibility Weighted Mahalanobis kernel) for SVM. The approach fuses generative and discriminative modeling techniques. With 20 benchmark data sets and with the MNIST data set it is shown that our new solution yields significantly better results than state-of-the-art methods.