 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-BDD: Leveraging Data Augmentations for Safe Autonomous Driving in Adverse Weather and Lighting
Aug 12, 2024High-autonomy vehicle functions rely on machine learning (ML) algorithms to understand the environment. Despite displaying remarkable performance in fair weather scenarios, perception algorithms are heavily affected by adverse weather and lighting conditions. To overcome these difficulties, ML engineers mainly rely on comprehensive real-world datasets. However, the difficulties in real-world data collection for critical areas of the operational design domain (ODD) often means synthetic data is required for perception training and safety validation. Thus, we present A-BDD, a large set of over 60,000 synthetically augmented images based on BDD100K that are equipped with semantic segmentation and bounding box annotations (inherited from the BDD100K dataset). The dataset contains augmented data for rain, fog, overcast and sunglare/shadow with varying intensity levels. We further introduce novel strategies utilizing feature-based image quality metrics like FID and CMMD, which help identify useful augmented and real-world data for ML training and testing. By conducting experiments on A-BDD, we provide evidence that data augmentations can play a pivotal role in closing performance gaps in adverse weather and lighting conditions.
Selecting Models based on the Risk of Damage Caused by Adversarial Attacks
Jan 28, 2023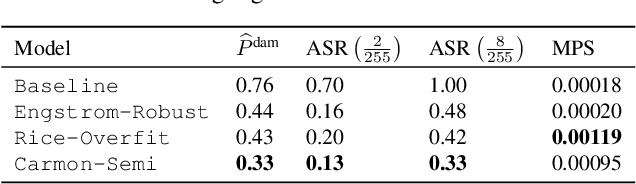
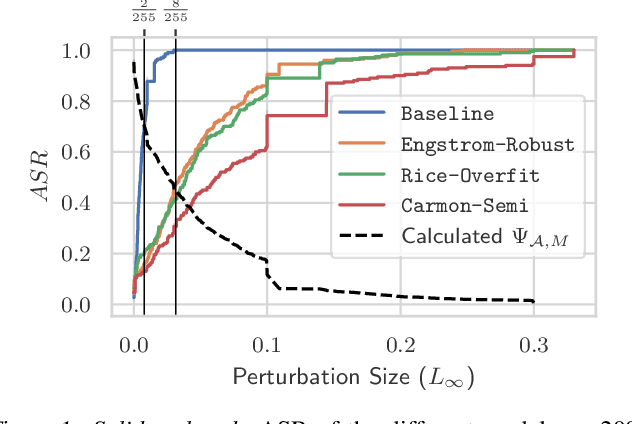
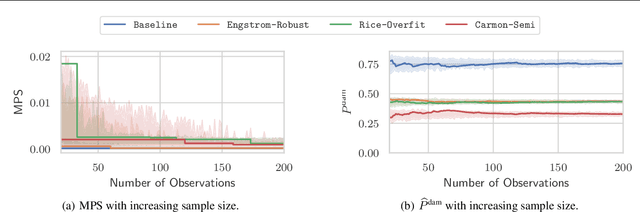
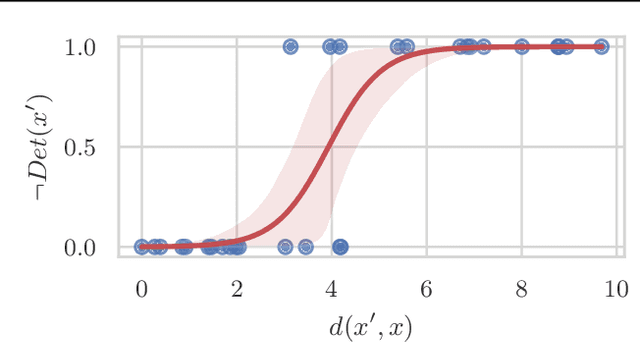
Regulation, legal liabilities, and societal concerns challenge the adoption of AI in safety and security-critical applications. One of the key concerns is that adversaries can cause harm by manipulating model predictions without being detected. Regulation hence demands an assessment of the risk of damage caused by adversaries. Yet, there is no method to translate this high-level demand into actionable metrics that quantify the risk of damage. In this article, we propose a method to model and statistically estimate the probability of damage arising from adversarial attacks. We show that our proposed estimator is statistically consistent and unbiased. In experiments, we demonstrate that the estimation results of our method have a clear and actionable interpretation and outperform conventional metrics. We then show how operators can use the estimation results to reliably select the model with the lowest risk.