 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Label Noise for Source-free Unsupervised Video Domain Adaptation
Nov 30, 2023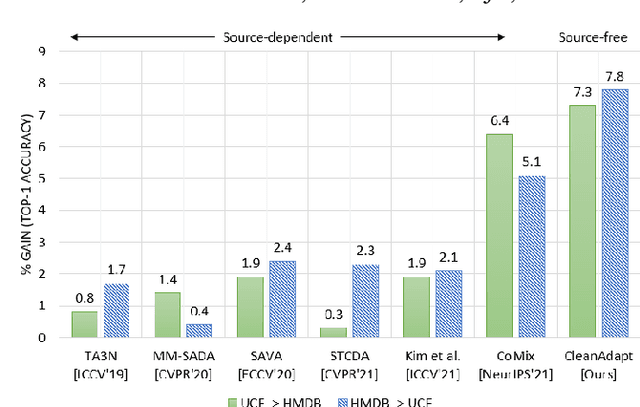
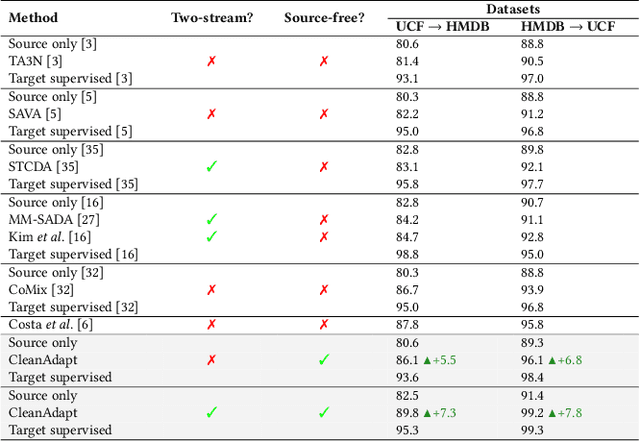
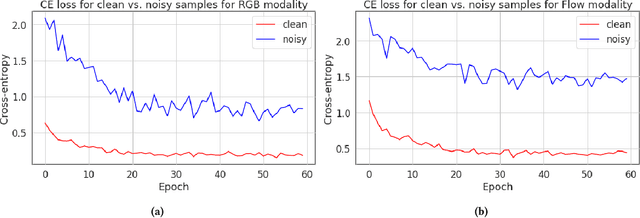
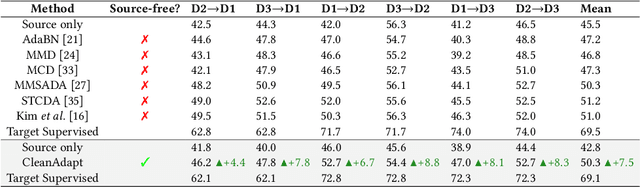
Despite the progress seen in classification methods, current approaches for handling videos with distribution shifts in source and target domains remain source-dependent as they require access to the source data during the adaptation stage. In this paper, we present a self-training based source-free video domain adaptation approach to address this challenge by bridging the gap between the source and the target domains. We use the source pre-trained model to generate pseudo-labels for the target domain samples, which are inevitably noisy. Thus, we treat the problem of source-free video domain adaptation as learning from noisy labels and argue that the samples with correct pseudo-labels can help us in adaptation. To this end, we leverage the cross-entropy loss as an indicator of the correctness of the pseudo-labels and use the resulting small-loss samples from the target domain for fine-tuning the model. We further enhance the adaptation performance by implementing a teacher-student framework, in which the teacher, which is updated gradually, produces reliable pseudo-labels. Meanwhile, the student undergoes fine-tuning on the target domain videos using these generated pseudo-labels to improve its performance. Extensive experimental evaluations show that our methods, termed as CleanAdapt, CleanAdapt + TS, achieve state-of-the-art results, outperforming the existing approaches on various open datasets. Our source code is publicly available at https://avijit9.github.io/CleanAdapt.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
A Fully Convolutional Neural Network based Structured Prediction Approach Towards the Retinal Vessel Segmentation
Nov 16, 2016
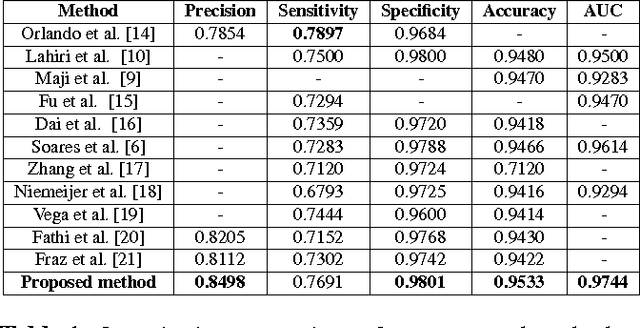

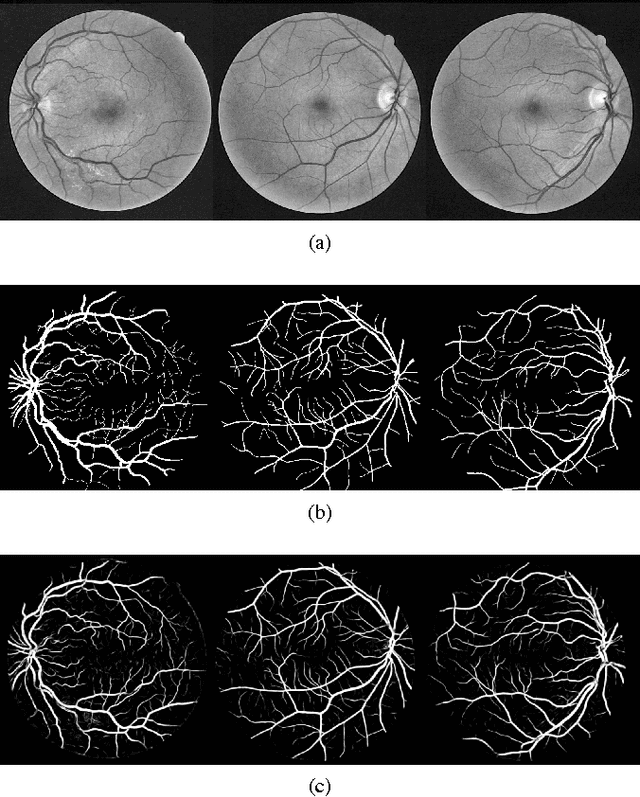
Automatic segmentation of retinal blood vessels from fundus images plays an important role in the computer aided diagnosis of retinal diseases. The task of blood vessel segmentation is challenging due to the extreme variations in morphology of the vessels against noisy background. In this paper, we formulate the segmentation task as a multi-label inference task and utilize the implicit advantages of the combination of convolutional neural networks and structured prediction. Our proposed convolutional neural network based model achieves strong performance and significantly outperforms the state-of-the-art for automatic retinal blood vessel segmentation on DRIVE dataset with 95.33% accuracy and 0.974 AUC score.