 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos
Paper and Code
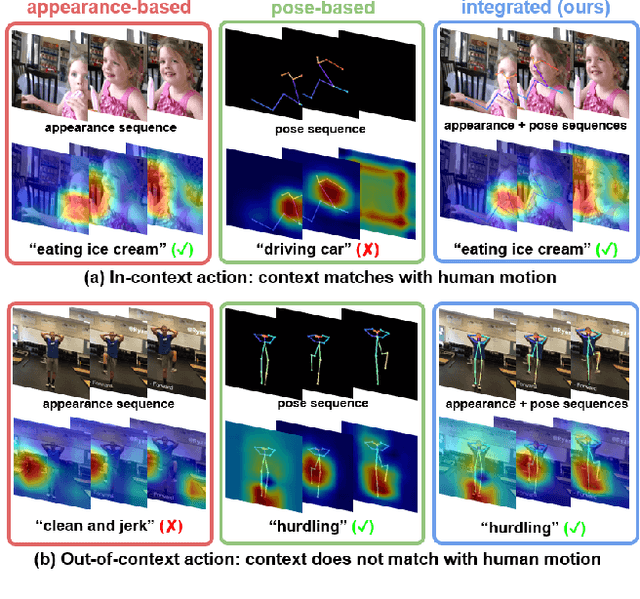
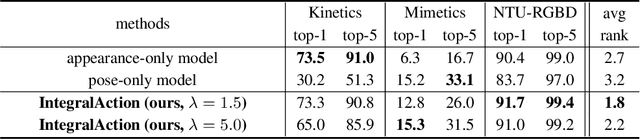
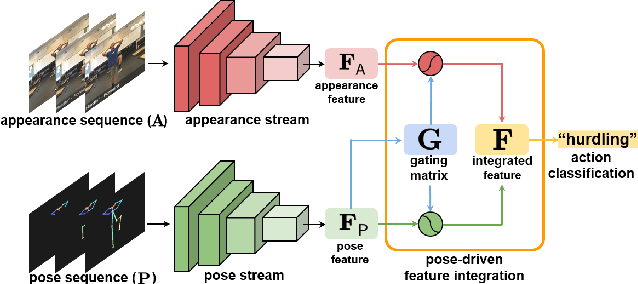

Most current action recognition methods heavily rely on appearance information by taking an RGB sequence of entire image regions as input. While being effective in exploiting contextual information around humans, e.g., human appearance and scene category, they are easily fooled by out-of-context action videos where the contexts do not exactly match with target actions. In contrast, pose-based methods, which takes a sequence of human skeletons only as input, suffer from inaccurate pose estimation or ambiguity of human pose per se. Integrating these two approaches has turned out to be non-trivial; training a model with both appearance and pose ends up with a strong bias towards appearance and does not generalize well to unseen videos. To address this problem, we propose to learn pose-driven feature integration that dynamically combines appearance and pose streams by observing pose features on the fly. The main idea is to let the pose stream decide how much and which appearance information is used in integration based on whether the given pose information is reliable or not. We show that the proposed IntegralAction achieves highly robust performance across in-context and out-of-context action video datasets.