 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforMatcher: Match-to-Match Attention for Semantic Correspondence
Paper and Code
May 23, 2022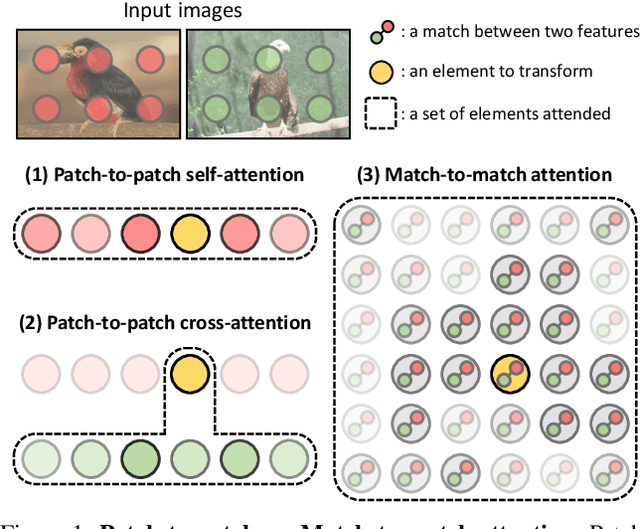
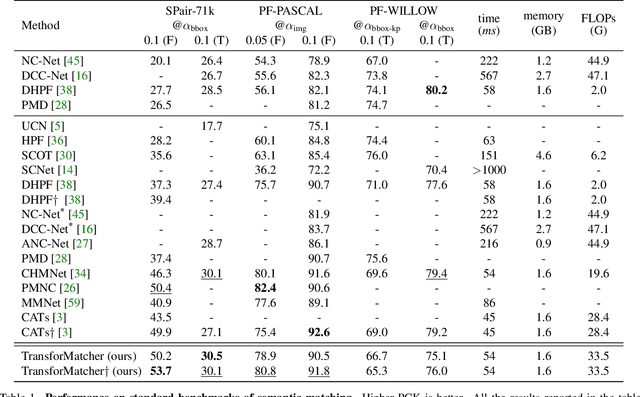
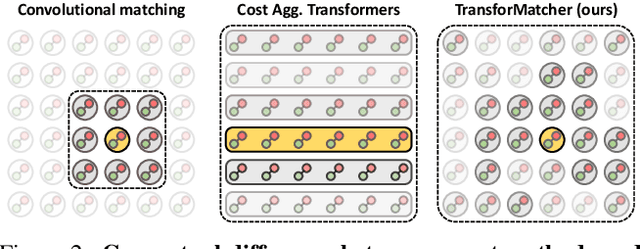
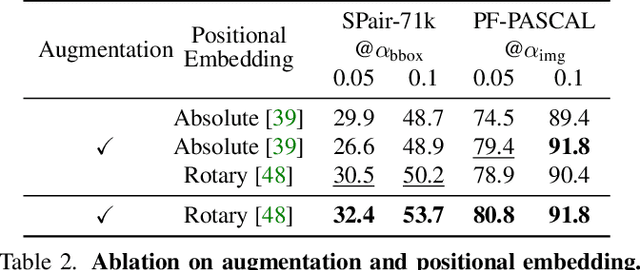
Establishing correspondences between images remains a challenging task, especially under large appearance changes due to different viewpoints or intra-class variations. In this work, we introduce a strong semantic image matching learner, dubbed TransforMatcher, which builds on the success of transformer networks in vision domains. Unlike existing convolution- or attention-based schemes for correspondence, TransforMatcher performs global match-to-match attention for precise match localization and dynamic refinement. To handle a large number of matches in a dense correlation map, we develop a light-weight attention architecture to consider the global match-to-match interactions. We also propose to utilize a multi-channel correlation map for refinement, treating the multi-level scores as features instead of a single score to fully exploit the richer layer-wise semantics. In experiments, TransforMatcher sets a new state of the art on SPair-71k while performing on par with existing SOTA methods on the PF-PASCAL dataset.