 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROBOGATE: Adaptive Failure Discovery for Safe Robot Policy Deployment via Two-Stage Boundary-Focused Sampling
Mar 23, 2026Deploying learned robot manipulation policies in industrial settings requires rigorous pre-deployment validation, yet exhaustive testing across high-dimensional parameter spaces is intractable. We present ROBOGATE, a deployment risk management framework that combines physics-based simulation with a two-stage adaptive sampling strategy to efficiently discover failure boundaries in the operational parameter space. Stage 1 employs Latin Hypercube Sampling (LHS) across an 8-dimensional parameter space to establish a coarse failure landscape from 20,000 uniformly distributed experiments. Stage 2 applies boundary-focused sampling that concentrates 10,000 additional experiments in the 30-70% success rate transition zone, enabling precise failure boundary mapping. Using NVIDIA Isaac Sim with Newton physics, we evaluate a scripted pick-and-place controller on two robot embodiments -- Franka Panda (7-DOF) and UR5e (6-DOF) -- across 30,000 total experiments. Our logistic regression risk model achieves an AUC of 0.780 on the combined dataset (vs. 0.754 for Stage 1 alone), identifies a closed-form failure boundary equation, and reveals four universal danger zones affecting both robot platforms. We further demonstrate the framework on VLA (Vision-Language-Action) model evaluation, where Octo-Small achieves 0.0% success rate on 68 adversarial scenarios versus 100% for the scripted baseline -- a 100-point gap that underscores the challenge of deploying foundation models in industrial settings. ROBOGATE is open-source and runs on a single GPU workstation.
Learning Rotation-Equivariant Features for Visual Correspondence
Mar 25, 2023Extracting discriminative local features that are invariant to imaging variations is an integral part of establishing correspondences between images. In this work, we introduce a self-supervised learning framework to extract discriminative rotation-invariant descriptors using group-equivariant CNNs. Thanks to employing group-equivariant CNNs, our method effectively learns to obtain rotation-equivariant features and their orientations explicitly, without having to perform sophisticated data augmentations. The resultant features and their orientations are further processed by group aligning, a novel invariant mapping technique that shifts the group-equivariant features by their orientations along the group dimension. Our group aligning technique achieves rotation-invariance without any collapse of the group dimension and thus eschews loss of discriminability. The proposed method is trained end-to-end in a self-supervised manner, where we use an orientation alignment loss for the orientation estimation and a contrastive descriptor loss for robust local descriptors to geometric/photometric variations. Our method demonstrates state-of-the-art matching accuracy among existing rotation-invariant descriptors under varying rotation and also shows competitive results when transferred to the task of keypoint matching and camera pose estimation.
Self-Supervised Equivariant Learning for Oriented Keypoint Detection
Apr 19, 2022
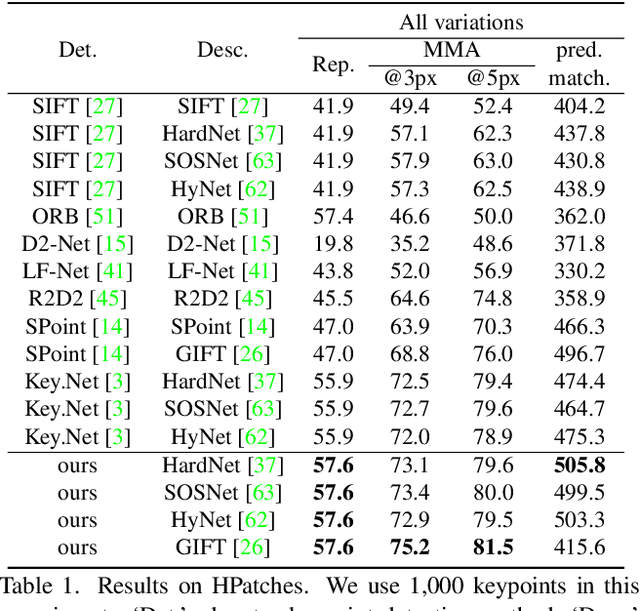
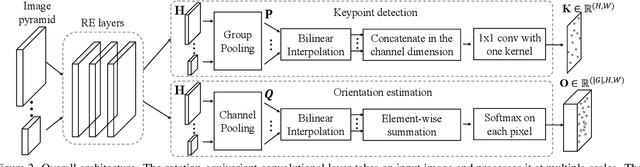
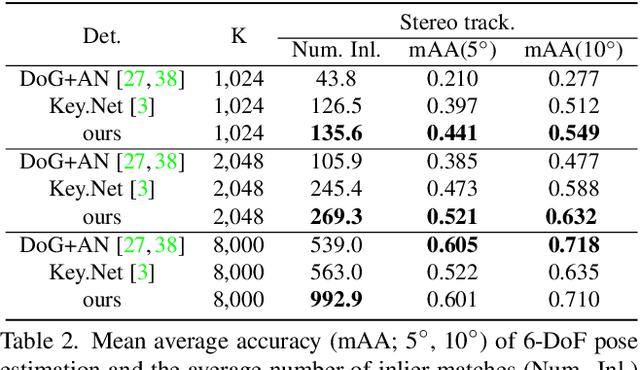
Detecting robust keypoints from an image is an integral part of many computer vision problems, and the characteristic orientation and scale of keypoints play an important role for keypoint description and matching. Existing learning-based methods for keypoint detection rely on standard translation-equivariant CNNs but often fail to detect reliable keypoints against geometric variations. To learn to detect robust oriented keypoints, we introduce a self-supervised learning framework using rotation-equivariant CNNs. We propose a dense orientation alignment loss by an image pair generated by synthetic transformations for training a histogram-based orientation map. Our method outperforms the previous methods on an image matching benchmark and a camera pose estimation benchmark.
Reflection and Rotation Symmetry Detection via Equivariant Learning
Mar 31, 2022
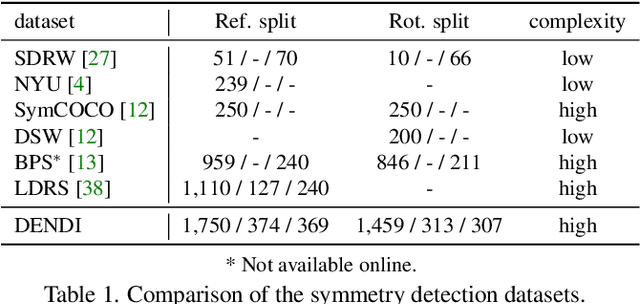
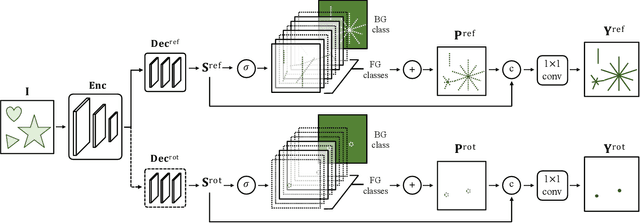
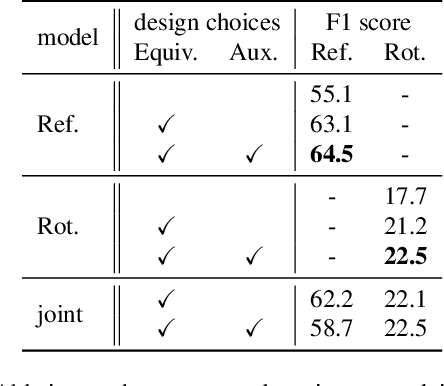
The inherent challenge of detecting symmetries stems from arbitrary orientations of symmetry patterns; a reflection symmetry mirrors itself against an axis with a specific orientation while a rotation symmetry matches its rotated copy with a specific orientation. Discovering such symmetry patterns from an image thus benefits from an equivariant feature representation, which varies consistently with reflection and rotation of the image. In this work, we introduce a group-equivariant convolutional network for symmetry detection, dubbed EquiSym, which leverages equivariant feature maps with respect to a dihedral group of reflection and rotation. The proposed network is built end-to-end with dihedrally-equivariant layers and trained to output a spatial map for reflection axes or rotation centers. We also present a new dataset, DENse and DIverse symmetry (DENDI), which mitigates limitations of existing benchmarks for reflection and rotation symmetry detection. Experiments show that our method achieves the state of the arts in symmetry detection on LDRS and DENDI datasets.