 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Align Network with Knowledge Distillation for Efficient Denoising
Mar 18, 2021
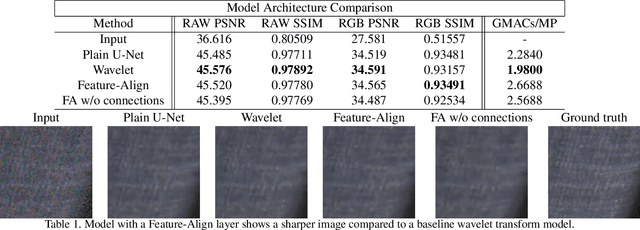
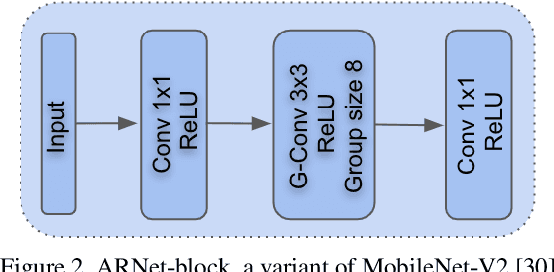
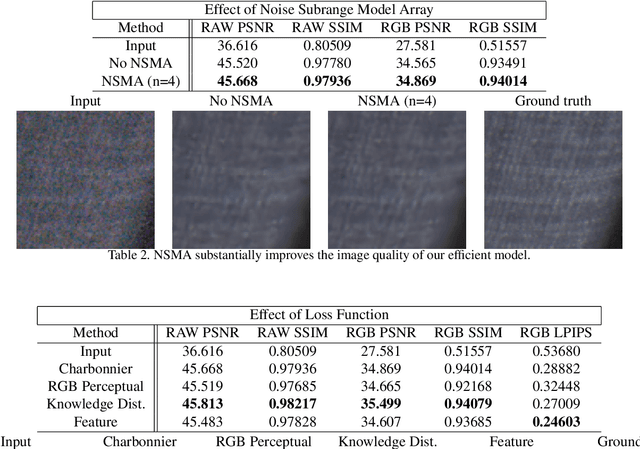
We propose an efficient neural network for RAW image denoising. Although neural network-based denoising has been extensively studied for image restoration, little attention has been given to efficient denoising for compute limited and power sensitive devices, such as smartphones and smartwatches. In this paper, we present a novel architecture and a suite of training techniques for high quality denoising in mobile devices. Our work is distinguished by three main contributions. (1) Feature-Align layer that modulates the activations of an encoder-decoder architecture with the input noisy images. The auto modulation layer enforces attention to spatially varying noise that tend to be "washed away" by successive application of convolutions and non-linearity. (2) A novel Feature Matching Loss that allows knowledge distillation from large denoising networks in the form of a perceptual content loss. (3) Empirical analysis of our efficient model trained to specialize on different noise subranges. This opens additional avenue for model size reduction by sacrificing memory for compute. Extensive experimental validation shows that our efficient model produces high quality denoising results that compete with state-of-the-art large networks, while using significantly fewer parameters and MACs. On the Darmstadt Noise Dataset benchmark, we achieve a PSNR of 48.28dB, while using 263 times fewer MACs, and 17.6 times fewer parameters than the state-of-the-art network, which achieves 49.12dB.
Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter
Jul 14, 2020
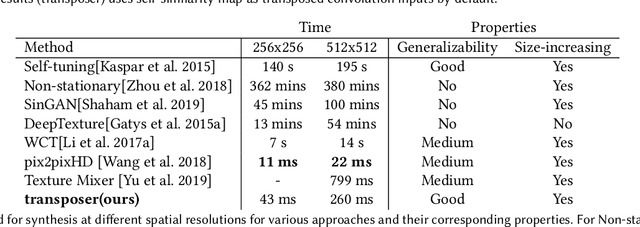
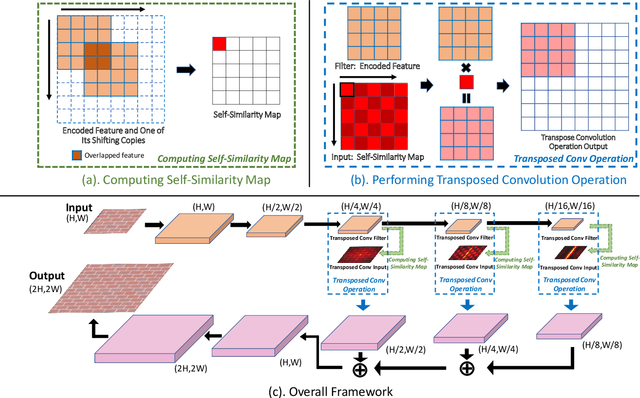
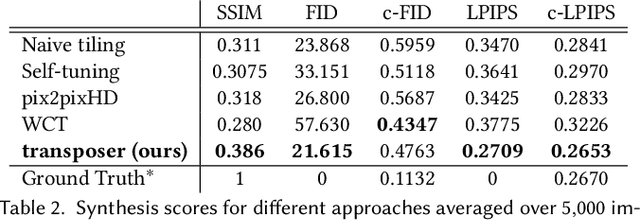
Conventional CNNs for texture synthesis consist of a sequence of (de)-convolution and up/down-sampling layers, where each layer operates locally and lacks the ability to capture the long-term structural dependency required by texture synthesis. Thus, they often simply enlarge the input texture, rather than perform reasonable synthesis. As a compromise, many recent methods sacrifice generalizability by training and testing on the same single (or fixed set of) texture image(s), resulting in huge re-training time costs for unseen images. In this work, based on the discovery that the assembling/stitching operation in traditional texture synthesis is analogous to a transposed convolution operation, we propose a novel way of using transposed convolution operation. Specifically, we directly treat the whole encoded feature map of the input texture as transposed convolution filters and the features' self-similarity map, which captures the auto-correlation information, as input to the transposed convolution. Such a design allows our framework, once trained, to be generalizable to perform synthesis of unseen textures with a single forward pass in nearly real-time. Our method achieves state-of-the-art texture synthesis quality based on various metrics. While self-similarity helps preserve the input textures' regular structural patterns, our framework can also take random noise maps for irregular input textures instead of self-similarity maps as transposed convolution inputs. It allows to get more diverse results as well as generate arbitrarily large texture outputs by directly sampling large noise maps in a single pass as well.
Unsupervised Video Interpolation Using Cycle Consistency
Jun 13, 2019
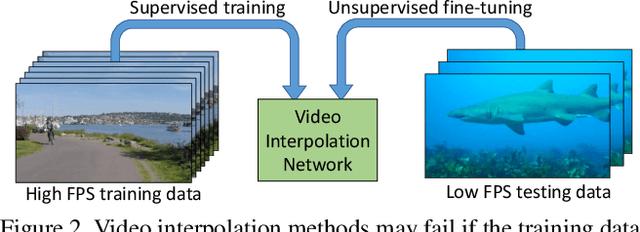
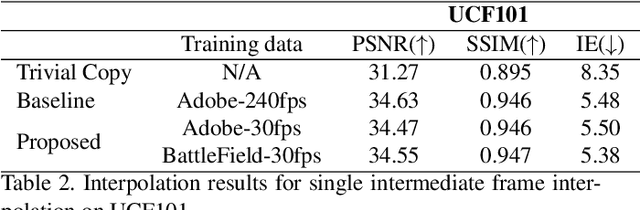
Learning to synthesize high frame rate videos via interpolation requires large quantities of high frame rate training videos, which, however, are scarce, especially at high resolutions. Here, we propose unsupervised techniques to synthesize high frame rate videos directly from low frame rate videos using cycle consistency. For a triplet of consecutive frames, we optimize models to minimize the discrepancy between the center frame and its cycle reconstruction, obtained by interpolating back from interpolated intermediate frames. This simple unsupervised constraint alone achieves results comparable with supervision using the ground truth intermediate frames. We further introduce a pseudo supervised loss term that enforces the interpolated frames to be consistent with predictions of a pre-trained interpolation model. The pseudo supervised loss term, used together with cycle consistency, can effectively adapt a pre-trained model to a new target domain. With no additional data and in a completely unsupervised fashion, our techniques significantly improve pre-trained models on new target domains, increasing PSNR values from 32.84dB to 33.05dB on the Slowflow and from 31.82dB to 32.53dB on the Sintel evaluation datasets.
Improving Semantic Segmentation via Video Propagation and Label Relaxation
Dec 04, 2018
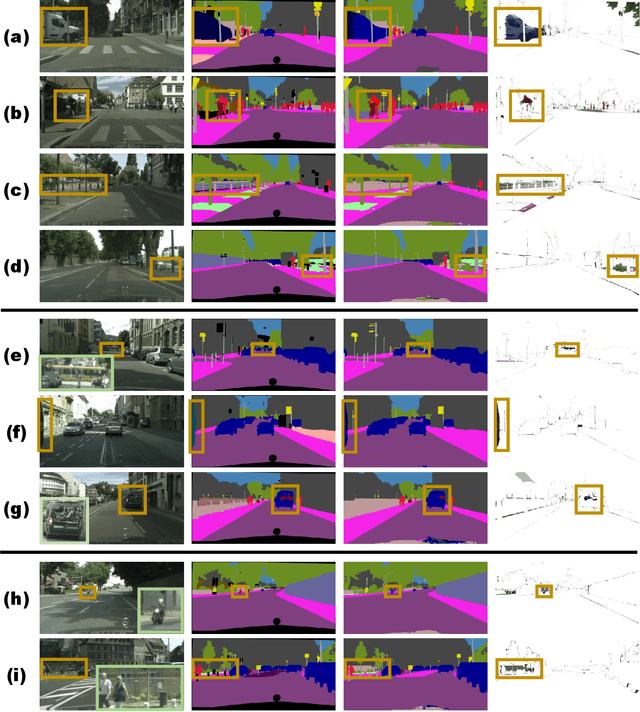

Semantic segmentation requires large amounts of pixel-wise annotations to learn accurate models. In this paper, we present a video prediction-based methodology to scale up training sets by synthesizing new training samples in order to improve the accuracy of semantic segmentation networks. We exploit video prediction models' ability to predict future frames in order to also predict future labels. A joint propagation strategy is also proposed to alleviate mis-alignments in synthesized samples. We demonstrate that training segmentation models on datasets augmented by the synthesized samples leads to significant improvements in accuracy. Furthermore, we introduce a novel boundary label relaxation technique that makes training robust to annotation noise and propagation artifacts along object boundaries. Our proposed methods achieve state-of-the-art mIoUs of 83.5% on Cityscapes and 82.9% on CamVid. Our single model, without model ensembles, achieves 72.8% mIoU on the KITTI semantic segmentation test set, which surpasses the winning entry of the ROB challenge 2018. Our code and videos can be found at https://nv-adlr.github.io/publication/2018-Segmentation.
Partial Convolution based Padding
Nov 28, 2018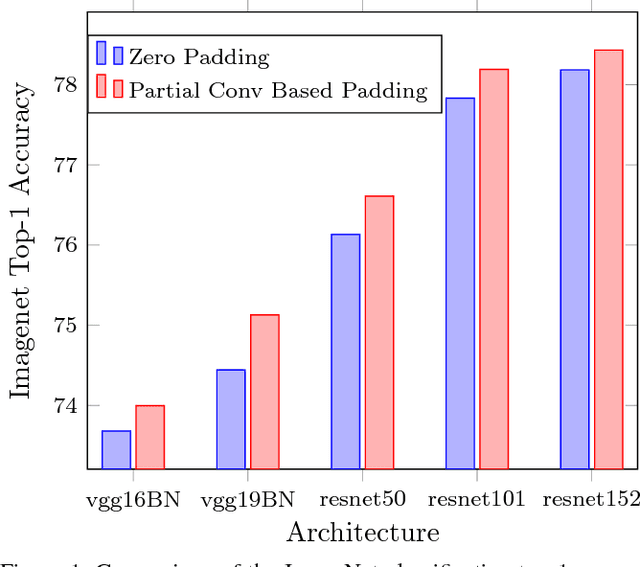
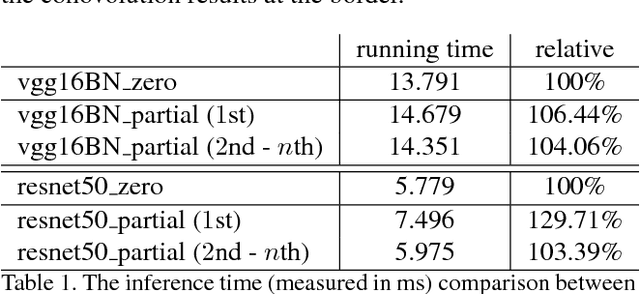
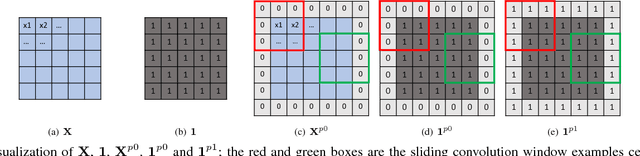
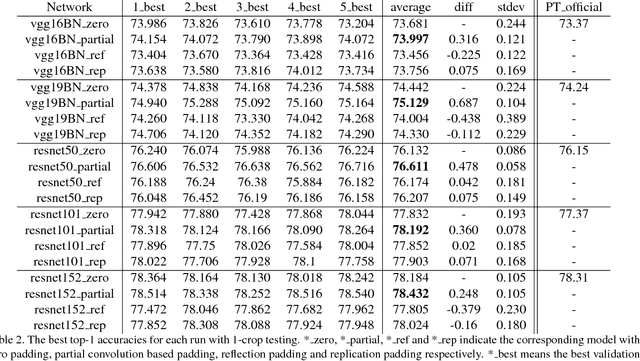
In this paper, we present a simple yet effective padding scheme that can be used as a drop-in module for existing convolutional neural networks. We call it partial convolution based padding, with the intuition that the padded region can be treated as holes and the original input as non-holes. Specifically, during the convolution operation, the convolution results are re-weighted near image borders based on the ratios between the padded area and the convolution sliding window area. Extensive experiments with various deep network models on ImageNet classification and semantic segmentation demonstrate that the proposed padding scheme consistently outperforms standard zero padding with better accuracy.
SDCNet: Video Prediction Using Spatially-Displaced Convolution
Nov 02, 2018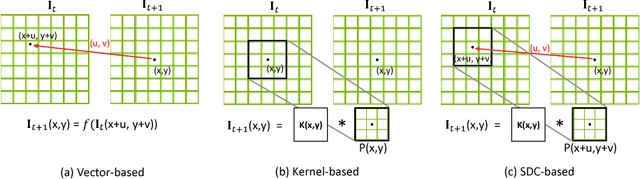
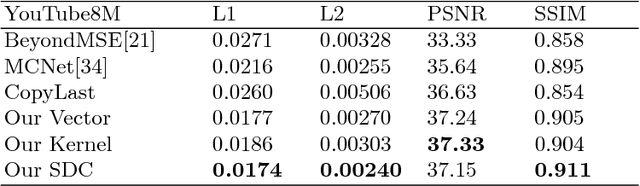
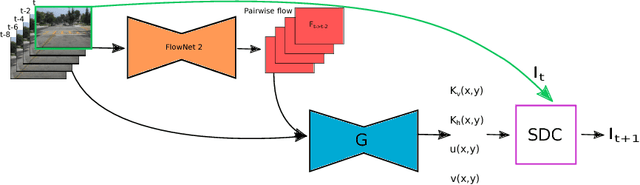
We present an approach for high-resolution video frame prediction by conditioning on both past frames and past optical flows. Previous approaches rely on resampling past frames, guided by a learned future optical flow, or on direct generation of pixels. Resampling based on flow is insufficient because it cannot deal with disocclusions. Generative models currently lead to blurry results. Recent approaches synthesis a pixel by convolving input patches with a predicted kernel. However, their memory requirement increases with kernel size. Here, we spatially-displaced convolution (SDC) module for video frame prediction. We learn a motion vector and a kernel for each pixel and synthesize a pixel by applying the kernel at a displaced location in the source image, defined by the predicted motion vector. Our approach inherits the merits of both vector-based and kernel-based approaches, while ameliorating their respective disadvantages. We train our model on 428K unlabelled 1080p video game frames. Our approach produces state-of-the-art results, achieving an SSIM score of 0.904 on high-definition YouTube-8M videos, 0.918 on Caltech Pedestrian videos. Our model handles large motion effectively and synthesizes crisp frames with consistent motion.
Image Inpainting for Irregular Holes Using Partial Convolutions
Apr 20, 2018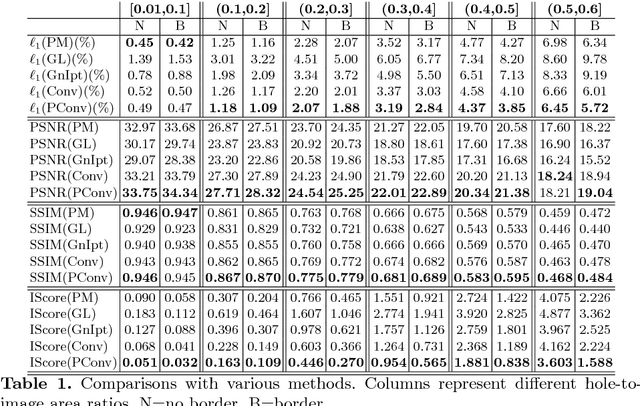

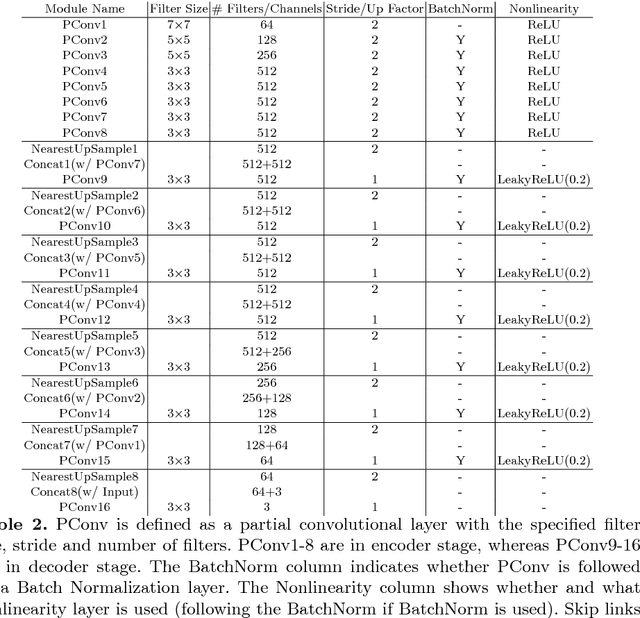

Existing deep learning based image inpainting methods use a standard convolutional network over the corrupted image, using convolutional filter responses conditioned on both valid pixels as well as the substitute values in the masked holes (typically the mean value). This often leads to artifacts such as color discrepancy and blurriness. Post-processing is usually used to reduce such artifacts, but are expensive and may fail. We propose the use of partial convolutions, where the convolution is masked and renormalized to be conditioned on only valid pixels. We further include a mechanism to automatically generate an updated mask for the next layer as part of the forward pass. Our model outperforms other methods for irregular masks. We show qualitative and quantitative comparisons with other methods to validate our approach.