 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-Time Human-AI Musical Co-Performance: Accompaniment Generation with Latent Diffusion Models and MAX/MSP
Apr 08, 2026We present a framework for real-time human-AI musical co-performance, in which a latent diffusion model generates instrumental accompaniment in response to a live stream of context audio. The system combines a MAX/MSP front-end-handling real-time audio input, buffering, and playback-with a Python inference server running the generative model, communicating via OSC/UDP messages. This allows musicians to perform in MAX/MSP - a well-established, real-time capable environment - while interacting with a large-scale Python-based generative model, overcoming the fundamental disconnect between real-time music tools and state-of-the-art AI models. We formulate accompaniment generation as a sliding-window look-ahead protocol, training the model to predict future audio from partial context, where system latency is a critical constraint. To reduce latency, we apply consistency distillation to our diffusion model, achieving a 5.4x reduction in sampling time, with both models achieving real-time operation. Evaluated on musical coherence, beat alignment, and audio quality, both models achieve strong performance in the Retrospective regime and degrade gracefully as look-ahead increases. These results demonstrate the feasibility of diffusion-based real-time accompaniment and expose the fundamental trade-off between model latency, look-ahead depth, and generation quality that any such system must navigate.
Interpreting Graphic Notation with MusicLDM: An AI Improvisation of Cornelius Cardew's Treatise
Dec 12, 2024
This work presents a novel method for composing and improvising music inspired by Cornelius Cardew's Treatise, using AI to bridge graphic notation and musical expression. By leveraging OpenAI's ChatGPT to interpret the abstract visual elements of Treatise, we convert these graphical images into descriptive textual prompts. These prompts are then input into MusicLDM, a pre-trained latent diffusion model designed for music generation. We introduce a technique called "outpainting," which overlaps sections of AI-generated music to create a seamless and cohesive composition. We demostrate a new perspective on performing and interpreting graphic scores, showing how AI can transform visual stimuli into sound and expand the creative possibilities in contemporary/experimental music composition. Musical pieces are available at https://bit.ly/TreatiseAI
Improving Source Extraction with Diffusion and Consistency Models
Dec 09, 2024In this work, we demonstrate the integration of a score-matching diffusion model into a deterministic architecture for time-domain musical source extraction, resulting in enhanced audio quality. To address the typically slow iterative sampling process of diffusion models, we apply consistency distillation and reduce the sampling process to a single step, achieving performance comparable to that of diffusion models, and with two or more steps, even surpassing them. Trained on the Slakh2100 dataset for four instruments (bass, drums, guitar, and piano), our model shows significant improvements across objective metrics compared to baseline methods. Sound examples are available at https://consistency-separation.github.io/.
Multi-Track MusicLDM: Towards Versatile Music Generation with Latent Diffusion Model
Sep 04, 2024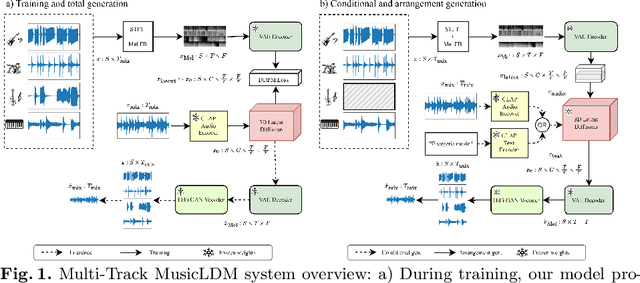


Diffusion models have shown promising results in cross-modal generation tasks involving audio and music, such as text-to-sound and text-to-music generation. These text-controlled music generation models typically focus on generating music by capturing global musical attributes like genre and mood. However, music composition is a complex, multilayered task that often involves musical arrangement as an integral part of the process. This process involves composing each instrument to align with existing ones in terms of beat, dynamics, harmony, and melody, requiring greater precision and control over tracks than text prompts usually provide. In this work, we address these challenges by extending the MusicLDM, a latent diffusion model for music, into a multi-track generative model. By learning the joint probability of tracks sharing a context, our model is capable of generating music across several tracks that correspond well to each other, either conditionally or unconditionally. Additionally, our model is capable of arrangement generation, where the model can generate any subset of tracks given the others (e.g., generating a piano track complementing given bass and drum tracks). We compared our model with an existing multi-track generative model and demonstrated that our model achieves considerable improvements across objective metrics for both total and arrangement generation tasks.
Latent CLAP Loss for Better Foley Sound Synthesis
Mar 18, 2024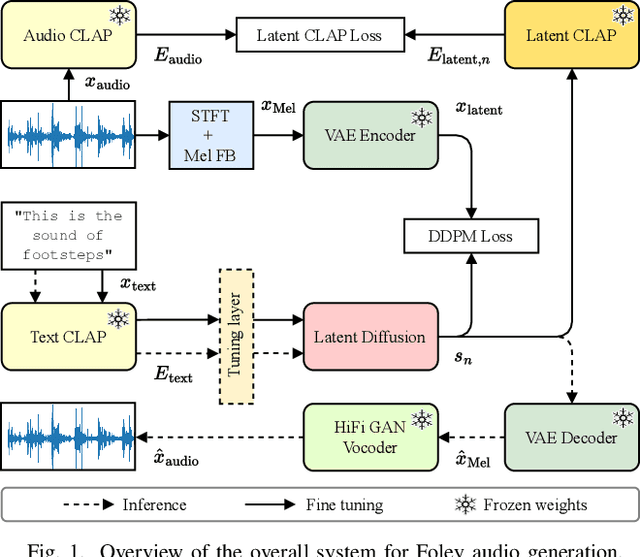
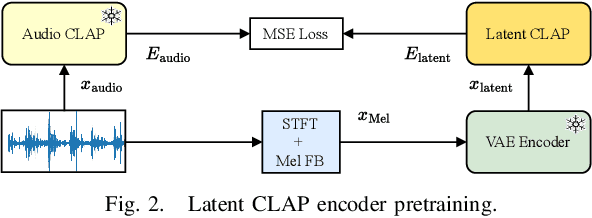
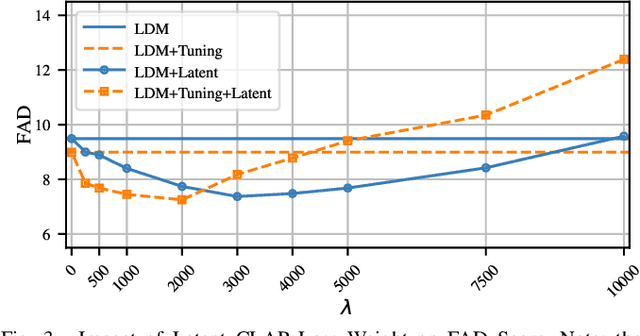
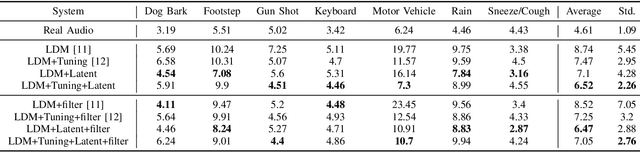
Foley sound generation, the art of creating audio for multimedia, has recently seen notable advancements through text-conditioned latent diffusion models. These systems use multimodal text-audio representation models, such as Contrastive Language-Audio Pretraining (CLAP), whose objective is to map corresponding audio and text prompts into a joint embedding space. AudioLDM, a text-to-audio model, was the winner of the DCASE2023 task 7 Foley sound synthesis challenge. The winning system fine-tuned the model for specific audio classes and applied a post-filtering method using CLAP similarity scores between output audio and input text at inference time, requiring the generation of extra samples, thus reducing data generation efficiency. We introduce a new loss term to enhance Foley sound generation in AudioLDM without post-filtering. This loss term uses a new module based on the CLAP mode-Latent CLAP encode-to align the latent diffusion output with real audio in a shared CLAP embedding space. Our experiments demonstrate that our method effectively reduces the Frechet Audio Distance (FAD) score of the generated audio and eliminates the need for post-filtering, thus enhancing generation efficiency.