 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Variational Auto-Encoder Architectures, Configurations, and Datasets for Generative Music Explainable AI
Nov 14, 2023Generative AI models for music and the arts in general are increasingly complex and hard to understand. The field of eXplainable AI (XAI) seeks to make complex and opaque AI models such as neural networks more understandable to people. One approach to making generative AI models more understandable is to impose a small number of semantically meaningful attributes on generative AI models. This paper contributes a systematic examination of the impact that different combinations of Variational Auto-Encoder models (MeasureVAE and AdversarialVAE), configurations of latent space in the AI model (from 4 to 256 latent dimensions), and training datasets (Irish folk, Turkish folk, Classical, and pop) have on music generation performance when 2 or 4 meaningful musical attributes are imposed on the generative model. To date there have been no systematic comparisons of such models at this level of combinatorial detail. Our findings show that MeasureVAE has better reconstruction performance than AdversarialVAE which has better musical attribute independence. Results demonstrate that MeasureVAE was able to generate music across music genres with interpretable musical dimensions of control, and performs best with low complexity music such a pop and rock. We recommend that a 32 or 64 latent dimensional space is optimal for 4 regularised dimensions when using MeasureVAE to generate music across genres. Our results are the first detailed comparisons of configurations of state-of-the-art generative AI models for music and can be used to help select and configure AI models, musical features, and datasets for more understandable generation of music.
Exploring XAI for the Arts: Explaining Latent Space in Generative Music
Aug 10, 2023



Explainable AI has the potential to support more interactive and fluid co-creative AI systems which can creatively collaborate with people. To do this, creative AI models need to be amenable to debugging by offering eXplainable AI (XAI) features which are inspectable, understandable, and modifiable. However, currently there is very little XAI for the arts. In this work, we demonstrate how a latent variable model for music generation can be made more explainable; specifically we extend MeasureVAE which generates measures of music. We increase the explainability of the model by: i) using latent space regularisation to force some specific dimensions of the latent space to map to meaningful musical attributes, ii) providing a user interface feedback loop to allow people to adjust dimensions of the latent space and observe the results of these changes in real-time, iii) providing a visualisation of the musical attributes in the latent space to help people understand and predict the effect of changes to latent space dimensions. We suggest that in doing so we bridge the gap between the latent space and the generated musical outcomes in a meaningful way which makes the model and its outputs more explainable and more debuggable.
HiSSNet: Sound Event Detection and Speaker Identification via Hierarchical Prototypical Networks for Low-Resource Headphones
Mar 13, 2023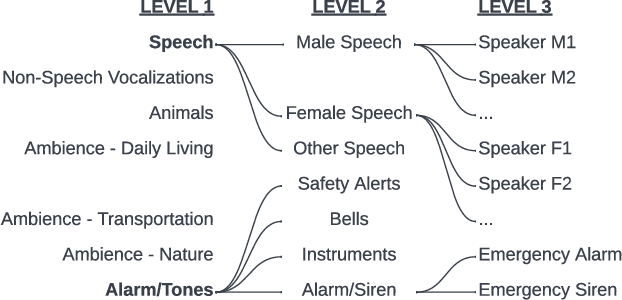



Modern noise-cancelling headphones have significantly improved users' auditory experiences by removing unwanted background noise, but they can also block out sounds that matter to users. Machine learning (ML) models for sound event detection (SED) and speaker identification (SID) can enable headphones to selectively pass through important sounds; however, implementing these models for a user-centric experience presents several unique challenges. First, most people spend limited time customizing their headphones, so the sound detection should work reasonably well out of the box. Second, the models should be able to learn over time the specific sounds that are important to users based on their implicit and explicit interactions. Finally, such models should have a small memory footprint to run on low-power headphones with limited on-chip memory. In this paper, we propose addressing these challenges using HiSSNet (Hierarchical SED and SID Network). HiSSNet is an SEID (SED and SID) model that uses a hierarchical prototypical network to detect both general and specific sounds of interest and characterize both alarm-like and speech sounds. We show that HiSSNet outperforms an SEID model trained using non-hierarchical prototypical networks by 6.9 - 8.6 percent. When compared to state-of-the-art (SOTA) models trained specifically for SED or SID alone, HiSSNet achieves similar or better performance while reducing the memory footprint required to support multiple capabilities on-device.