 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"It is okay to be uncommon": Quantizing Sound Event Detection Networks on Hardware Accelerators with Uncommon Sub-Byte Support
Apr 05, 2024



If our noise-canceling headphones can understand our audio environments, they can then inform us of important sound events, tune equalization based on the types of content we listen to, and dynamically adjust noise cancellation parameters based on audio scenes to further reduce distraction. However, running multiple audio understanding models on headphones with a limited energy budget and on-chip memory remains a challenging task. In this work, we identify a new class of neural network accelerators (e.g., NE16 on GAP9) that allows network weights to be quantized to different common (e.g., 8 bits) and uncommon bit-widths (e.g., 3 bits). We then applied a differentiable neural architecture search to search over the optimal bit-widths of a network on two different sound event detection tasks with potentially different requirements on quantization and prediction granularity (i.e., classification vs. embeddings for few-shot learning). We further evaluated our quantized models on actual hardware, showing that we reduce memory usage, inference latency, and energy consumption by an average of 62%, 46%, and 61% respectively compared to 8-bit models while maintaining floating point performance. Our work sheds light on the benefits of such accelerators on sound event detection tasks when combined with an appropriate search method.
HiSSNet: Sound Event Detection and Speaker Identification via Hierarchical Prototypical Networks for Low-Resource Headphones
Mar 13, 2023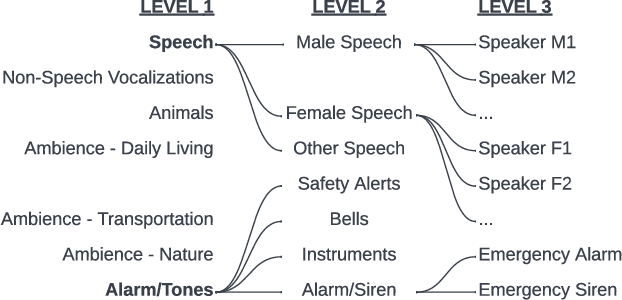



Modern noise-cancelling headphones have significantly improved users' auditory experiences by removing unwanted background noise, but they can also block out sounds that matter to users. Machine learning (ML) models for sound event detection (SED) and speaker identification (SID) can enable headphones to selectively pass through important sounds; however, implementing these models for a user-centric experience presents several unique challenges. First, most people spend limited time customizing their headphones, so the sound detection should work reasonably well out of the box. Second, the models should be able to learn over time the specific sounds that are important to users based on their implicit and explicit interactions. Finally, such models should have a small memory footprint to run on low-power headphones with limited on-chip memory. In this paper, we propose addressing these challenges using HiSSNet (Hierarchical SED and SID Network). HiSSNet is an SEID (SED and SID) model that uses a hierarchical prototypical network to detect both general and specific sounds of interest and characterize both alarm-like and speech sounds. We show that HiSSNet outperforms an SEID model trained using non-hierarchical prototypical networks by 6.9 - 8.6 percent. When compared to state-of-the-art (SOTA) models trained specifically for SED or SID alone, HiSSNet achieves similar or better performance while reducing the memory footprint required to support multiple capabilities on-device.