 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Identification of High Impact Research through Text and Image Analysis
Paper and Code
May 20, 2020
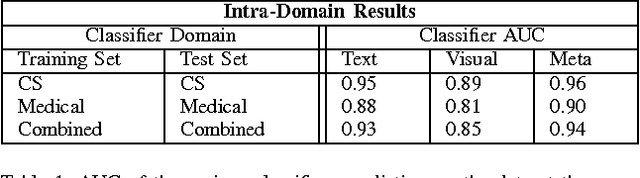
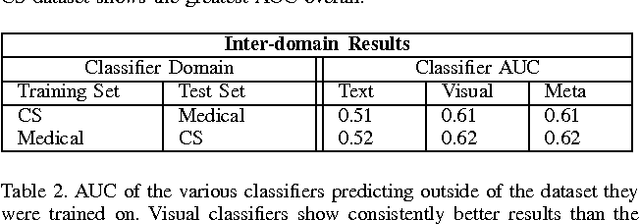
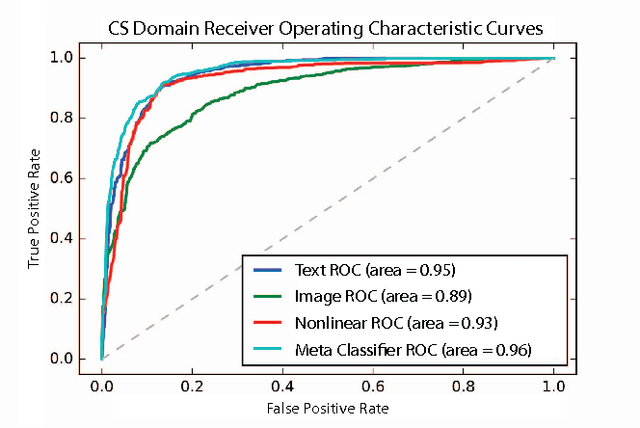
The volume of academic paper submissions and publications is growing at an ever increasing rate. While this flood of research promises progress in various fields, the sheer volume of output inherently increases the amount of noise. We present a system to automatically separate papers with a high from those with a low likelihood of gaining citations as a means to quickly find high impact, high quality research. Our system uses both a visual classifier, useful for surmising a document's overall appearance, and a text classifier, for making content-informed decisions. Current work in the field focuses on small datasets composed of papers from individual conferences. Attempts to use similar techniques on larger datasets generally only considers excerpts of the documents such as the abstract, potentially throwing away valuable data. We rectify these issues by providing a dataset composed of PDF documents and citation counts spanning a decade of output within two separate academic domains: computer science and medicine. This new dataset allows us to expand on current work in the field by generalizing across time and academic domain. Moreover, we explore inter-domain prediction models - evaluating a classifier's performance on a domain it was not trained on - to shed further insight on this important problem.