 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-conditioning Single-channel Target Speaker Extraction using Conformer-based Architectures
May 27, 2022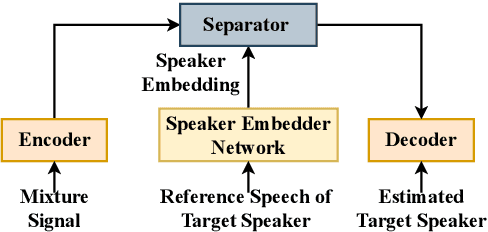
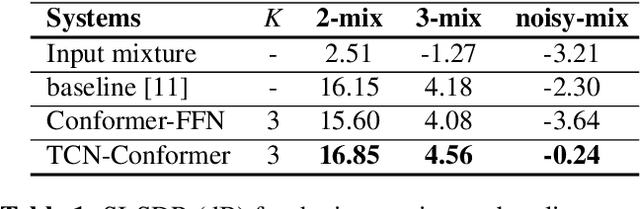
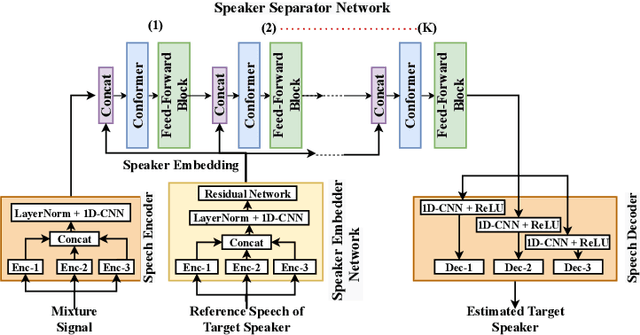
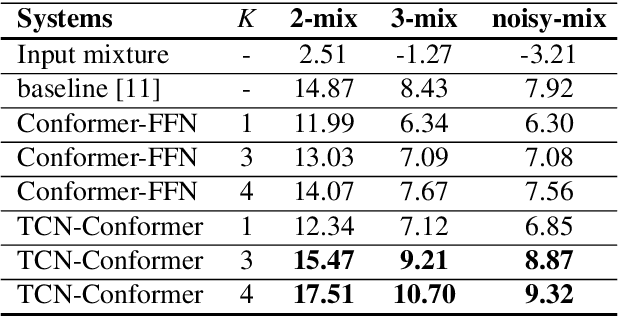
Target speaker extraction aims at extracting the target speaker from a mixture of multiple speakers exploiting auxiliary information about the target speaker. In this paper, we consider a complete time-domain target speaker extraction system consisting of a speaker embedder network and a speaker separator network which are jointly trained in an end-to-end learning process. We propose two different architectures for the speaker separator network which are based on the convolutional augmented transformer (conformer). The first architecture uses stacks of conformer and external feed-forward blocks (Conformer-FFN), while the second architecture uses stacks of temporal convolutional network (TCN) and conformer blocks (TCN-Conformer). Experimental results for 2-speaker mixtures, 3-speaker mixtures, and noisy mixtures of 2-speakers show that among the proposed separator networks, the TCN-Conformer significantly improves the target speaker extraction performance compared to the Conformer-FFN and a TCN-based baseline system.
Reduction of Subjective Listening Effort for TV Broadcast Signals with Recurrent Neural Networks
Nov 02, 2021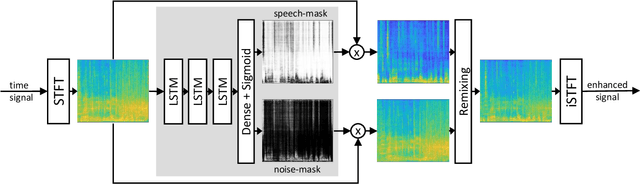
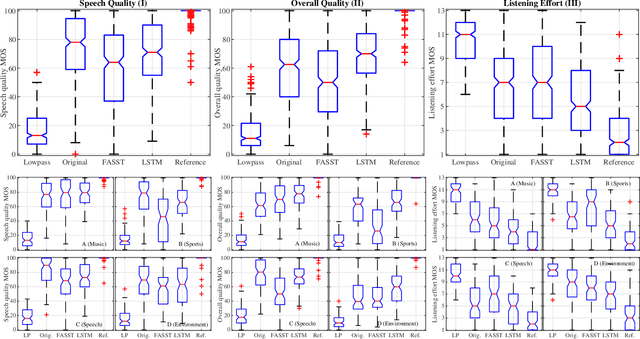


Listening to the audio of TV broadcast signals can be challenging for hearing-impaired as well as normal-hearing listeners, especially when background sounds are prominent or too loud compared to the speech signal. This can result in a reduced satisfaction and increased listening effort of the listeners. Since the broadcast sound is usually premixed, we perform a subjective evaluation for quantifying the potential of speech enhancement systems based on audio source separation and recurrent neural networks (RNN). Recently, RNNs have shown promising results in the context of sound source separation and real-time signal processing. In this paper, we separate the speech from the background signals and remix the separated sounds at a higher signal-to-noise ratio. This differs from classic speech enhancement, where usually only the extracted speech signal is exploited. The subjective evaluation with 20 normal-hearing subjects on real TV-broadcast material shows that our proposed enhancement system is able to reduce the listening effort by around 2 points on a 13-point listening effort rating scale and increases the perceived sound quality compared to the original mixture.
Speaker-conditioned Target Speaker Extraction based on Customized LSTM Cells
Apr 09, 2021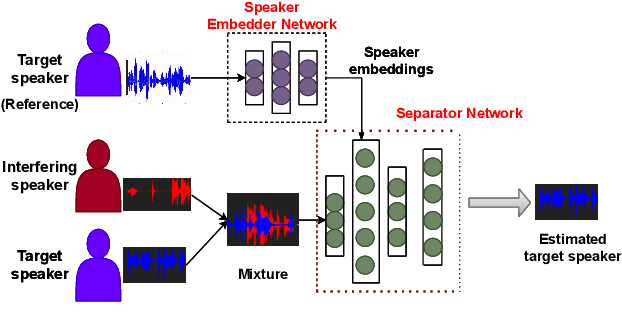
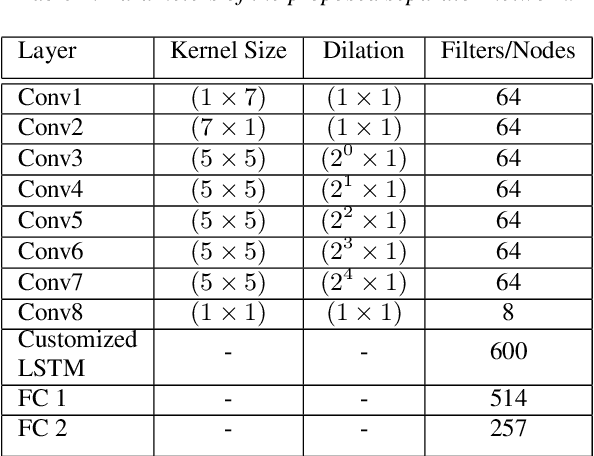
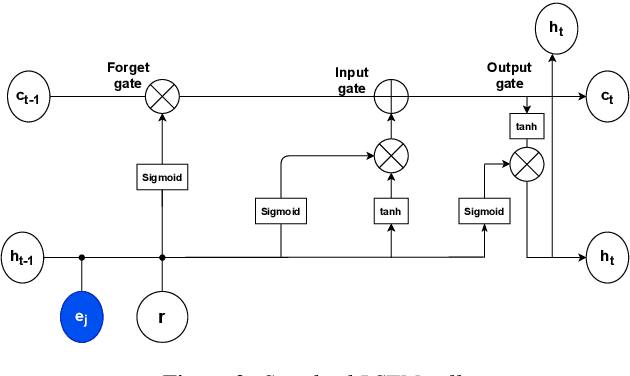
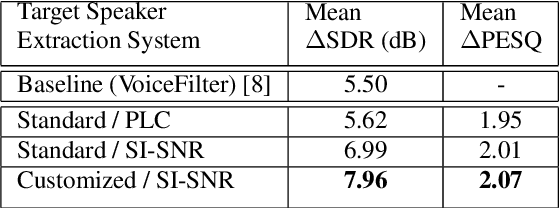
Speaker-conditioned target speaker extraction systems rely on auxiliary information about the target speaker to extract the target speaker signal from a mixture of multiple speakers. Typically, a deep neural network is applied to isolate the relevant target speaker characteristics. In this paper, we focus on a single-channel target speaker extraction system based on a CNN-LSTM separator network and a speaker embedder network requiring reference speech of the target speaker. In the LSTM layer of the separator network, we propose to customize the LSTM cells in order to only remember the specific voice patterns corresponding to the target speaker by modifying the information processing in the forget gate. Experimental results for two-speaker mixtures using the Librispeech dataset show that this customization significantly improves the target speaker extraction performance compared to using standard LSTM cells.