 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow bit rate binaural link for improved ultra low-latency low-complexity multichannel speech enhancement in Hearing Aids
Paper and Code
Jul 17, 2023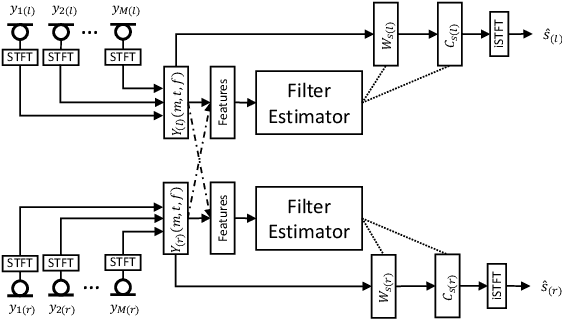
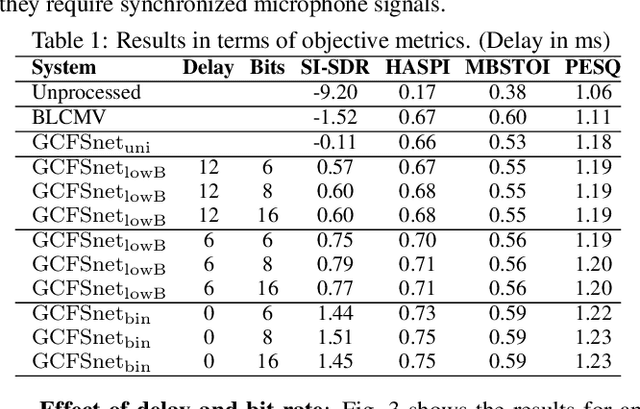
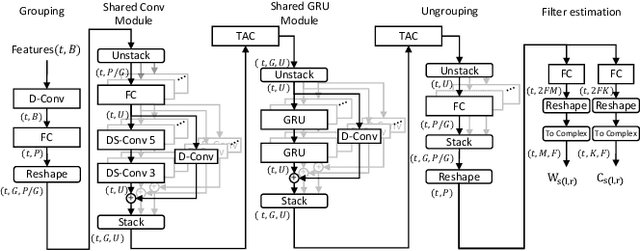

Speech enhancement in hearing aids is a challenging task since the hardware limits the number of possible operations and the latency needs to be in the range of only a few milliseconds. We propose a deep-learning model compatible with these limitations, which we refer to as Group-Communication Filter-and-Sum Network (GCFSnet). GCFSnet is a causal multiple-input single output enhancement model using filter-and-sum processing in the time-frequency domain and a multi-frame deep post filter. All filters are complex-valued and are estimated by a deep-learning model using weight-sharing through Group Communication and quantization-aware training for reducing model size and computational footprint. For a further increase in performance, a low bit rate binaural link for delayed binaural features is proposed to use binaural information while retaining a latency of 2ms. The performance of an oracle binaural LCMV beamformer in non-low-latency configuration can be matched even by a unilateral configuration of the GCFSnet in terms of objective metrics.