 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROG$_{PL}$: Robust Open-Set Graph Learning via Region-Based Prototype Learning
Feb 29, 2024



Open-set graph learning is a practical task that aims to classify the known class nodes and to identify unknown class samples as unknowns. Conventional node classification methods usually perform unsatisfactorily in open-set scenarios due to the complex data they encounter, such as out-of-distribution (OOD) data and in-distribution (IND) noise. OOD data are samples that do not belong to any known classes. They are outliers if they occur in training (OOD noise), and open-set samples if they occur in testing. IND noise are training samples which are assigned incorrect labels. The existence of IND noise and OOD noise is prevalent, which usually cause the ambiguity problem, including the intra-class variety problem and the inter-class confusion problem. Thus, to explore robust open-set learning methods is necessary and difficult, and it becomes even more difficult for non-IID graph data.To this end, we propose a unified framework named ROG$_{PL}$ to achieve robust open-set learning on complex noisy graph data, by introducing prototype learning. In specific, ROG$_{PL}$ consists of two modules, i.e., denoising via label propagation and open-set prototype learning via regions. The first module corrects noisy labels through similarity-based label propagation and removes low-confidence samples, to solve the intra-class variety problem caused by noise. The second module learns open-set prototypes for each known class via non-overlapped regions and remains both interior and border prototypes to remedy the inter-class confusion problem.The two modules are iteratively updated under the constraints of classification loss and prototype diversity loss. To the best of our knowledge, the proposed ROG$_{PL}$ is the first robust open-set node classification method for graph data with complex noise.
Multi-level Cross-modal Alignment for Image Clustering
Jan 22, 2024Recently, the cross-modal pretraining model has been employed to produce meaningful pseudo-labels to supervise the training of an image clustering model. However, numerous erroneous alignments in a cross-modal pre-training model could produce poor-quality pseudo-labels and degrade clustering performance. To solve the aforementioned issue, we propose a novel \textbf{Multi-level Cross-modal Alignment} method to improve the alignments in a cross-modal pretraining model for downstream tasks, by building a smaller but better semantic space and aligning the images and texts in three levels, i.e., instance-level, prototype-level, and semantic-level. Theoretical results show that our proposed method converges, and suggests effective means to reduce the expected clustering risk of our method. Experimental results on five benchmark datasets clearly show the superiority of our new method.
Semantic-enhanced Image Clustering
Aug 21, 2022
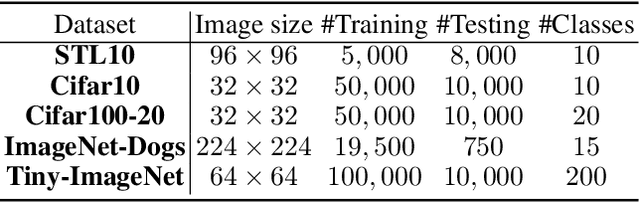
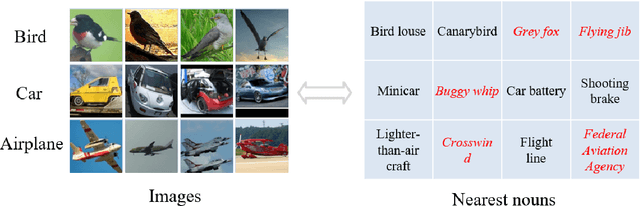
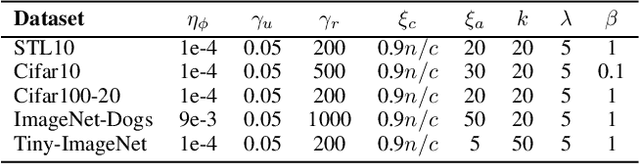
Image clustering is an important, and open challenge task in computer vision. Although many methods have been proposed to solve the image clustering task, they only explore images and uncover clusters according to the image features, thus are unable to distinguish visually similar but semantically different images. In this paper, we propose to investigate the task of image clustering with the help of visual-language pre-training model. Different from the zero-shot setting in which the class names are known, we only know the number of clusters in this setting. Therefore, how to map images to a proper semantic space and how to cluster images from both image and semantic spaces are two key problems. To solve the above problems, we propose a novel image clustering method guided by the visual-language pre-training model CLIP, named as \textbf{Semantic-enhanced Image Clustering (SIC)}. In this new method, we propose a method to map the given images to a proper semantic space first and efficient methods to generate pseudo-labels according to the relationships between images and semantics. Finally, we propose to perform clustering with the consistency learning in both image space and semantic space, in a self-supervised learning fashion. Theoretical result on convergence analysis shows that our proposed method can converge in sublinear speed. Theoretical analysis on expectation risk also shows that we can reduce the expectation risk by improving the neighborhood consistency or prediction confidence or reducing neighborhood imbalance. Experimental results on five benchmark datasets clearly show the superiority of our new method.