 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-enhanced Image Clustering
Paper and Code
Aug 21, 2022
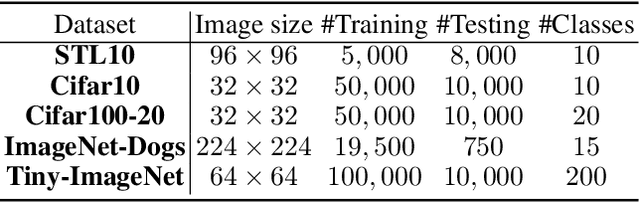
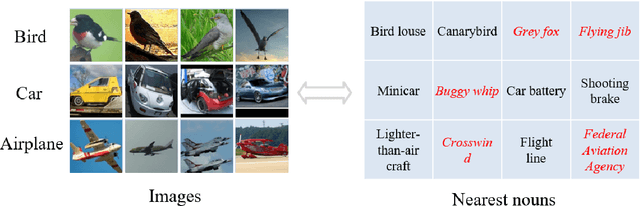
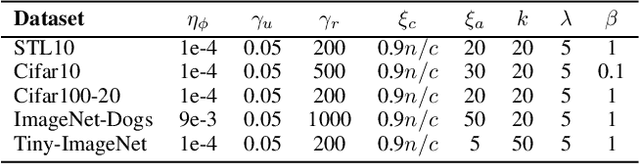
Image clustering is an important, and open challenge task in computer vision. Although many methods have been proposed to solve the image clustering task, they only explore images and uncover clusters according to the image features, thus are unable to distinguish visually similar but semantically different images. In this paper, we propose to investigate the task of image clustering with the help of visual-language pre-training model. Different from the zero-shot setting in which the class names are known, we only know the number of clusters in this setting. Therefore, how to map images to a proper semantic space and how to cluster images from both image and semantic spaces are two key problems. To solve the above problems, we propose a novel image clustering method guided by the visual-language pre-training model CLIP, named as \textbf{Semantic-enhanced Image Clustering (SIC)}. In this new method, we propose a method to map the given images to a proper semantic space first and efficient methods to generate pseudo-labels according to the relationships between images and semantics. Finally, we propose to perform clustering with the consistency learning in both image space and semantic space, in a self-supervised learning fashion. Theoretical result on convergence analysis shows that our proposed method can converge in sublinear speed. Theoretical analysis on expectation risk also shows that we can reduce the expectation risk by improving the neighborhood consistency or prediction confidence or reducing neighborhood imbalance. Experimental results on five benchmark datasets clearly show the superiority of our new method.