 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Cross-modal Alignment for Image Clustering
Jan 22, 2024Recently, the cross-modal pretraining model has been employed to produce meaningful pseudo-labels to supervise the training of an image clustering model. However, numerous erroneous alignments in a cross-modal pre-training model could produce poor-quality pseudo-labels and degrade clustering performance. To solve the aforementioned issue, we propose a novel \textbf{Multi-level Cross-modal Alignment} method to improve the alignments in a cross-modal pretraining model for downstream tasks, by building a smaller but better semantic space and aligning the images and texts in three levels, i.e., instance-level, prototype-level, and semantic-level. Theoretical results show that our proposed method converges, and suggests effective means to reduce the expected clustering risk of our method. Experimental results on five benchmark datasets clearly show the superiority of our new method.
Semantic-enhanced Image Clustering
Aug 21, 2022
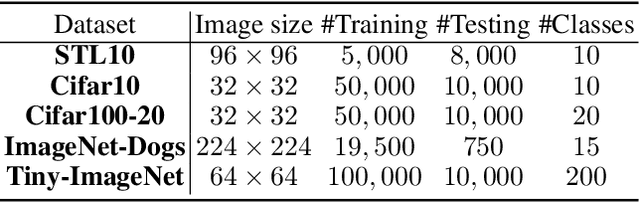
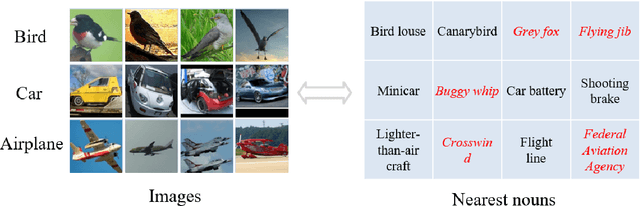
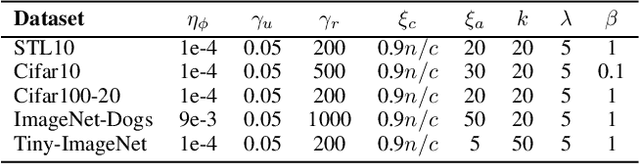
Image clustering is an important, and open challenge task in computer vision. Although many methods have been proposed to solve the image clustering task, they only explore images and uncover clusters according to the image features, thus are unable to distinguish visually similar but semantically different images. In this paper, we propose to investigate the task of image clustering with the help of visual-language pre-training model. Different from the zero-shot setting in which the class names are known, we only know the number of clusters in this setting. Therefore, how to map images to a proper semantic space and how to cluster images from both image and semantic spaces are two key problems. To solve the above problems, we propose a novel image clustering method guided by the visual-language pre-training model CLIP, named as \textbf{Semantic-enhanced Image Clustering (SIC)}. In this new method, we propose a method to map the given images to a proper semantic space first and efficient methods to generate pseudo-labels according to the relationships between images and semantics. Finally, we propose to perform clustering with the consistency learning in both image space and semantic space, in a self-supervised learning fashion. Theoretical result on convergence analysis shows that our proposed method can converge in sublinear speed. Theoretical analysis on expectation risk also shows that we can reduce the expectation risk by improving the neighborhood consistency or prediction confidence or reducing neighborhood imbalance. Experimental results on five benchmark datasets clearly show the superiority of our new method.
Deep Unsupervised Hashing with Latent Semantic Components
Mar 17, 2022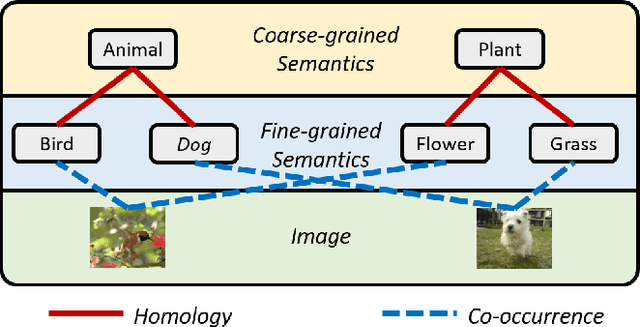
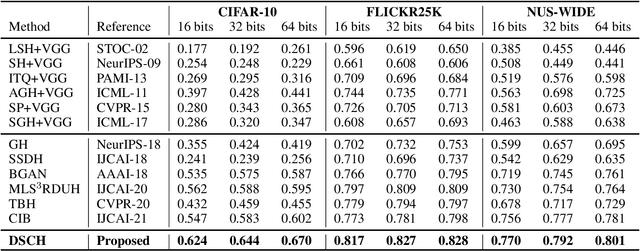
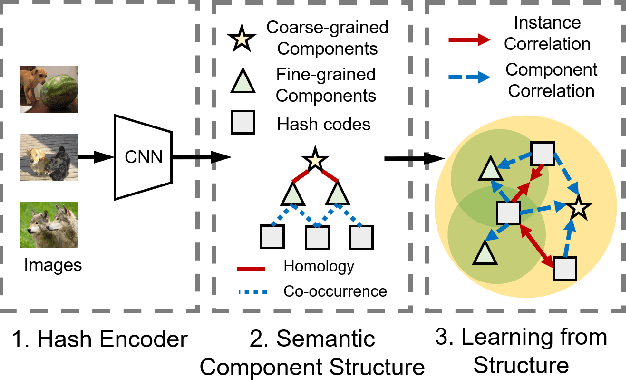
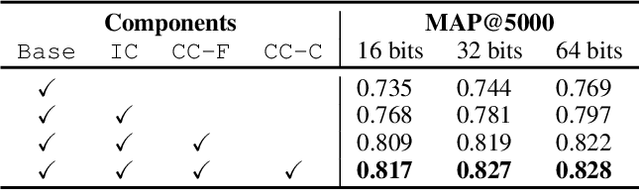
Deep unsupervised hashing has been appreciated in the regime of image retrieval. However, most prior arts failed to detect the semantic components and their relationships behind the images, which makes them lack discriminative power. To make up the defect, we propose a novel Deep Semantic Components Hashing (DSCH), which involves a common sense that an image normally contains a bunch of semantic components with homology and co-occurrence relationships. Based on this prior, DSCH regards the semantic components as latent variables under the Expectation-Maximization framework and designs a two-step iterative algorithm with the objective of maximum likelihood of training data. Firstly, DSCH constructs a semantic component structure by uncovering the fine-grained semantics components of images with a Gaussian Mixture Modal~(GMM), where an image is represented as a mixture of multiple components, and the semantics co-occurrence are exploited. Besides, coarse-grained semantics components, are discovered by considering the homology relationships between fine-grained components, and the hierarchy organization is then constructed. Secondly, DSCH makes the images close to their semantic component centers at both fine-grained and coarse-grained levels, and also makes the images share similar semantic components close to each other. Extensive experiments on three benchmark datasets demonstrate that the proposed hierarchical semantic components indeed facilitate the hashing model to achieve superior performance.