 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
Diffusion Priors for Variational Likelihood Estimation and Image Denoising
Oct 23, 2024



Real-world noise removal is crucial in low-level computer vision. Due to the remarkable generation capabilities of diffusion models, recent attention has shifted towards leveraging diffusion priors for image restoration tasks. However, existing diffusion priors-based methods either consider simple noise types or rely on approximate posterior estimation, limiting their effectiveness in addressing structured and signal-dependent noise commonly found in real-world images. In this paper, we build upon diffusion priors and propose adaptive likelihood estimation and MAP inference during the reverse diffusion process to tackle real-world noise. We introduce an independent, non-identically distributed likelihood combined with the noise precision (inverse variance) prior and dynamically infer the precision posterior using variational Bayes during the generation process. Meanwhile, we rectify the estimated noise variance through local Gaussian convolution. The final denoised image is obtained by propagating intermediate MAP solutions that balance the updated likelihood and diffusion prior. Additionally, we explore the local diffusion prior inherent in low-resolution diffusion models, enabling direct handling of high-resolution noisy images. Extensive experiments and analyses on diverse real-world datasets demonstrate the effectiveness of our method. Code is available at https://github.com/HUST-Tan/DiffusionVI.
Transfer CLIP for Generalizable Image Denoising
Mar 22, 2024



Image denoising is a fundamental task in computer vision. While prevailing deep learning-based supervised and self-supervised methods have excelled in eliminating in-distribution noise, their susceptibility to out-of-distribution (OOD) noise remains a significant challenge. The recent emergence of contrastive language-image pre-training (CLIP) model has showcased exceptional capabilities in open-world image recognition and segmentation. Yet, the potential for leveraging CLIP to enhance the robustness of low-level tasks remains largely unexplored. This paper uncovers that certain dense features extracted from the frozen ResNet image encoder of CLIP exhibit distortion-invariant and content-related properties, which are highly desirable for generalizable denoising. Leveraging these properties, we devise an asymmetrical encoder-decoder denoising network, which incorporates dense features including the noisy image and its multi-scale features from the frozen ResNet encoder of CLIP into a learnable image decoder to achieve generalizable denoising. The progressive feature augmentation strategy is further proposed to mitigate feature overfitting and improve the robustness of the learnable decoder. Extensive experiments and comparisons conducted across diverse OOD noises, including synthetic noise, real-world sRGB noise, and low-dose CT image noise, demonstrate the superior generalization ability of our method.
Image Denoising via Style Disentanglement
Sep 26, 2023



Image denoising is a fundamental task in low-level computer vision. While recent deep learning-based image denoising methods have achieved impressive performance, they are black-box models and the underlying denoising principle remains unclear. In this paper, we propose a novel approach to image denoising that offers both clear denoising mechanism and good performance. We view noise as a type of image style and remove it by incorporating noise-free styles derived from clean images. To achieve this, we design novel losses and network modules to extract noisy styles from noisy images and noise-free styles from clean images. The noise-free style induces low-response activations for noise features and high-response activations for content features in the feature space. This leads to the separation of clean contents from noise, effectively denoising the image. Unlike disentanglement-based image editing tasks that edit semantic-level attributes using styles, our main contribution lies in editing pixel-level attributes through global noise-free styles. We conduct extensive experiments on synthetic noise removal and real-world image denoising datasets (SIDD and DND), demonstrating the effectiveness of our method in terms of both PSNR and SSIM metrics. Moreover, we experimentally validate that our method offers good interpretability.
Unsupervised CT Metal Artifact Reduction by Plugging Diffusion Priors in Dual Domains
Aug 31, 2023



During the process of computed tomography (CT), metallic implants often cause disruptive artifacts in the reconstructed images, impeding accurate diagnosis. Several supervised deep learning-based approaches have been proposed for reducing metal artifacts (MAR). However, these methods heavily rely on training with simulated data, as obtaining paired metal artifact CT and clean CT data in clinical settings is challenging. This limitation can lead to decreased performance when applying these methods in clinical practice. Existing unsupervised MAR methods, whether based on learning or not, typically operate within a single domain, either in the image domain or the sinogram domain. In this paper, we propose an unsupervised MAR method based on the diffusion model, a generative model with a high capacity to represent data distributions. Specifically, we first train a diffusion model using CT images without metal artifacts. Subsequently, we iteratively utilize the priors embedded within the pre-trained diffusion model in both the sinogram and image domains to restore the degraded portions caused by metal artifacts. This dual-domain processing empowers our approach to outperform existing unsupervised MAR methods, including another MAR method based on the diffusion model, which we have qualitatively and quantitatively validated using synthetic datasets. Moreover, our method demonstrates superior visual results compared to both supervised and unsupervised methods on clinical datasets.
Score Priors Guided Deep Variational Inference for Unsupervised Real-World Single Image Denoising
Aug 09, 2023Real-world single image denoising is crucial and practical in computer vision. Bayesian inversions combined with score priors now have proven effective for single image denoising but are limited to white Gaussian noise. Moreover, applying existing score-based methods for real-world denoising requires not only the explicit train of score priors on the target domain but also the careful design of sampling procedures for posterior inference, which is complicated and impractical. To address these limitations, we propose a score priors-guided deep variational inference, namely ScoreDVI, for practical real-world denoising. By considering the deep variational image posterior with a Gaussian form, score priors are extracted based on easily accessible minimum MSE Non-$i.i.d$ Gaussian denoisers and variational samples, which in turn facilitate optimizing the variational image posterior. Such a procedure adaptively applies cheap score priors to denoising. Additionally, we exploit a Non-$i.i.d$ Gaussian mixture model and variational noise posterior to model the real-world noise. This scheme also enables the pixel-wise fusion of multiple image priors and variational image posteriors. Besides, we develop a noise-aware prior assignment strategy that dynamically adjusts the weight of image priors in the optimization. Our method outperforms other single image-based real-world denoising methods and achieves comparable performance to dataset-based unsupervised methods.
A Diffusion Probabilistic Prior for Low-Dose CT Image Denoising
May 25, 2023Low-dose computed tomography (CT) image denoising is crucial in medical image computing. Recent years have been remarkable improvement in deep learning-based methods for this task. However, training deep denoising neural networks requires low-dose and normal-dose CT image pairs, which are difficult to obtain in the clinic settings. To address this challenge, we propose a novel fully unsupervised method for low-dose CT image denoising, which is based on denoising diffusion probabilistic model -- a powerful generative model. First, we train an unconditional denoising diffusion probabilistic model capable of generating high-quality normal-dose CT images from random noise. Subsequently, the probabilistic priors of the pre-trained diffusion model are incorporated into a Maximum A Posteriori (MAP) estimation framework for iteratively solving the image denoising problem. Our method ensures the diffusion model produces high-quality normal-dose CT images while keeping the image content consistent with the input low-dose CT images. We evaluate our method on a widely used low-dose CT image denoising benchmark, and it outperforms several supervised low-dose CT image denoising methods in terms of both quantitative and visual performance.
Quantification of Local Metabolic Tumor Volume Changes by Registering Blended PET-CT Images for Prediction of Pathologic Tumor Response
Aug 24, 2018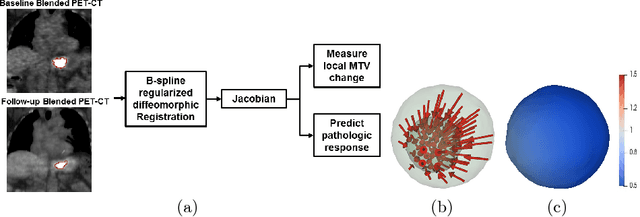
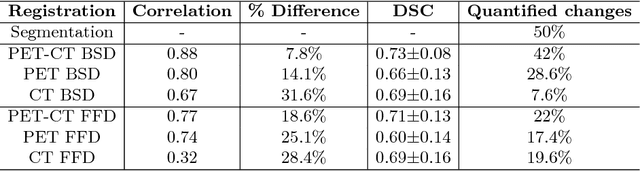

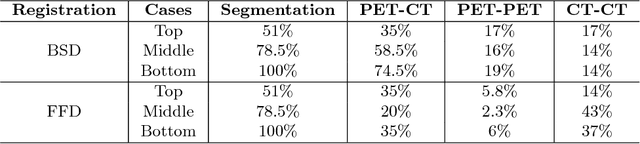
Quantification of local metabolic tumor volume (MTV) chan-ges after Chemo-radiotherapy would allow accurate tumor response evaluation. Currently, local MTV changes in esophageal (soft-tissue) cancer are measured by registering follow-up PET to baseline PET using the same transformation obtained by deformable registration of follow-up CT to baseline CT. Such approach is suboptimal because PET and CT capture fundamentally different properties (metabolic vs. anatomy) of a tumor. In this work we combined PET and CT images into a single blended PET-CT image and registered follow-up blended PET-CT image to baseline blended PET-CT image. B-spline regularized diffeomorphic registration was used to characterize the large MTV shrinkage. Jacobian of the resulting transformation was computed to measure the local MTV changes. Radiomic features (intensity and texture) were then extracted from the Jacobian map to predict pathologic tumor response. Local MTV changes calculated using blended PET-CT registration achieved the highest correlation with ground truth segmentation (R=0.88) compared to PET-PET (R=0.80) and CT-CT (R=0.67) registrations. Moreover, using blended PET-CT registration, the multivariate prediction model achieved the highest accuracy with only one Jacobian co-occurrence texture feature (accuracy=82.3%). This novel framework can replace the conventional approach that applies CT-CT transformation to the PET data for longitudinal evaluation of tumor response.