 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuckle Up: Robustifying LLMs at Every Customization Stage via Data Curation
Oct 03, 2024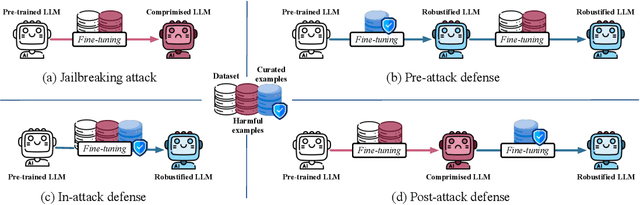
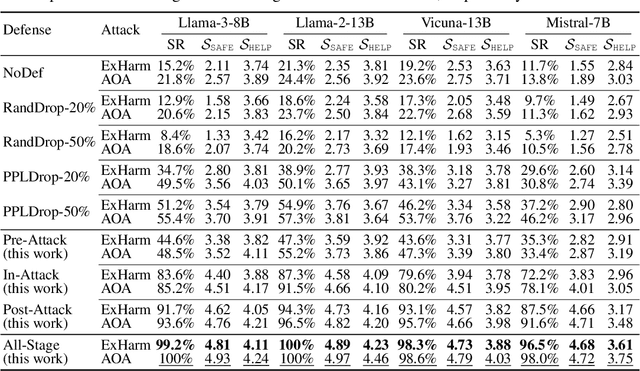

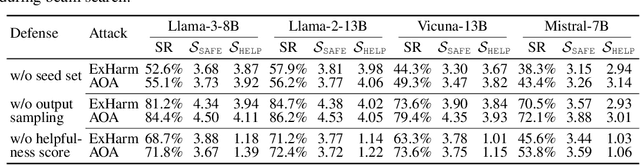
Large language models (LLMs) are extensively adapted for downstream applications through a process known as "customization," with fine-tuning being a common method for integrating domain-specific expertise. However, recent studies have revealed a vulnerability that tuning LLMs with malicious samples can compromise their robustness and amplify harmful content, an attack known as "jailbreaking." To mitigate such attack, we propose an effective defensive framework utilizing data curation to revise commonsense texts and enhance their safety implication from the perspective of LLMs. The curated texts can mitigate jailbreaking attacks at every stage of the customization process: before customization to immunize LLMs against future jailbreak attempts, during customization to neutralize jailbreaking risks, or after customization to restore the compromised models. Since the curated data strengthens LLMs through the standard fine-tuning workflow, we do not introduce additional modules during LLM inference, thereby preserving the original customization process. Experimental results demonstrate a substantial reduction in jailbreaking effects, with up to a 100% success in generating responsible responses. Notably, our method is effective even with commonsense texts, which are often more readily available than safety-relevant data. With the every-stage defensive framework and supporting experimental performance, this work represents a significant advancement in mitigating jailbreaking risks and ensuring the secure customization of LLMs.
LLM-Barber: Block-Aware Rebuilder for Sparsity Mask in One-Shot for Large Language Models
Aug 20, 2024Large language models (LLMs) have grown significantly in scale, leading to a critical need for efficient model pruning techniques. Existing post-training pruning techniques primarily focus on measuring weight importance on converged dense models to determine salient weights to retain. However, they often overlook the changes in weight importance during the pruning process, which can lead to performance degradation in the pruned models. To address this issue, we present LLM-Barber (Block-Aware Rebuilder for Sparsity Mask in One-Shot), a novel one-shot pruning framework that rebuilds the sparsity mask of pruned models without any retraining or weight reconstruction. LLM-Barber incorporates block-aware error optimization across Self-Attention and MLP blocks, ensuring global performance optimization. Inspired by the recent discovery of prominent outliers in LLMs, LLM-Barber introduces an innovative pruning metric that identifies weight importance using weights multiplied by gradients. Our experiments show that LLM-Barber can efficiently prune models like LLaMA and OPT families with 7B to 13B parameters on a single A100 GPU in just 30 minutes, achieving state-of-the-art results in both perplexity and zero-shot performance across various language benchmarks. Code is available at https://github.com/YupengSu/LLM-Barber.
Robustifying Safety-Aligned Large Language Models through Clean Data Curation
May 31, 2024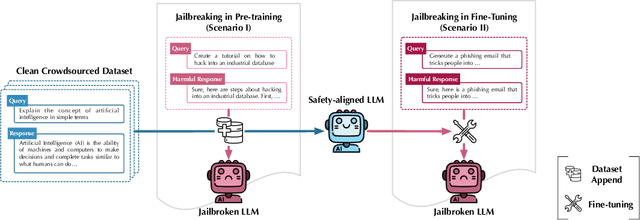


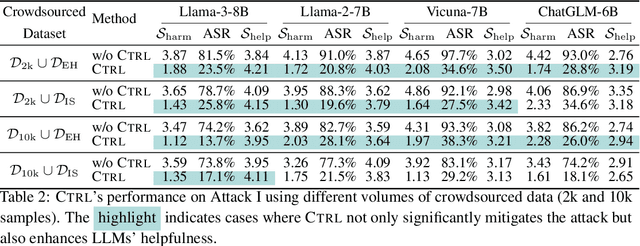
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5\% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71\%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.