 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Dataset for Understandable Medical Language Translation
Dec 04, 2020

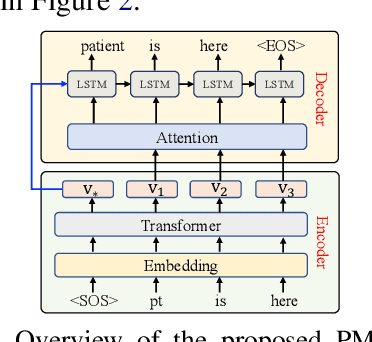

In this paper, we introduce MedLane -- a new human-annotated Medical Language translation dataset, to align professional medical sentences with layperson-understandable expressions. The dataset contains 12,801 training samples, 1,015 validation samples, and 1,016 testing samples. We then evaluate one naive and six deep learning-based approaches on the MedLane dataset, including directly copying, a statistical machine translation approach Moses, four neural machine translation approaches (i.e., the proposed PMBERT-MT model, Seq2Seq and its two variants), and a modified text summarization model PointerNet. To compare the results, we utilize eleven metrics, including three new measures specifically designed for this task. Finally, we discuss the limitations of MedLane and baselines, and point out possible research directions for this task.