 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQubitHD: A Stochastic Acceleration Method for HD Computing-Based Machine Learning
Dec 02, 2019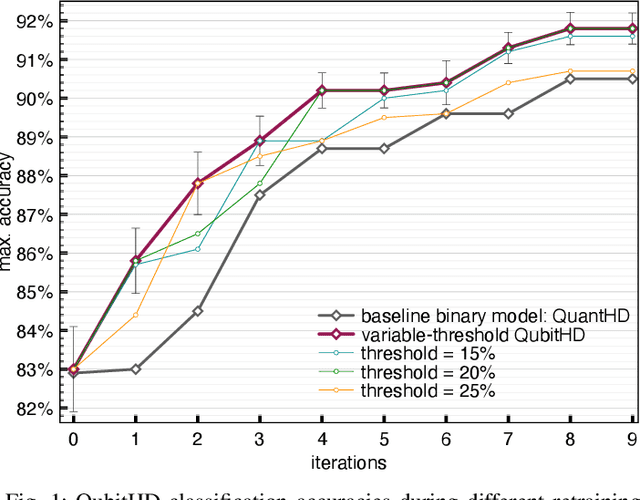
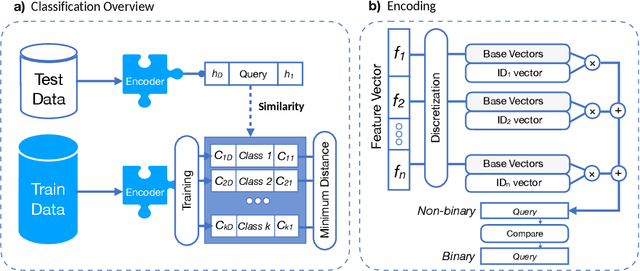
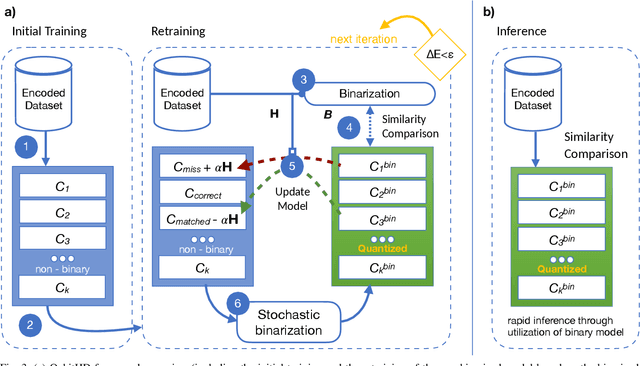
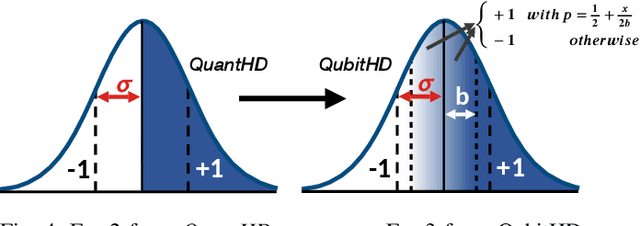
Machine Learning algorithms based on Brain-inspired Hyperdimensional (HD) computing imitate cognition by exploiting statistical properties of high-dimensional vector spaces. It is a promising solution for achieving high energy-efficiency in different machine learning tasks, such as classification, semi-supervised learning and clustering. A weakness of existing HD computing-based ML algorithms is the fact that they have to be binarized for achieving very high energy-efficiency. At the same time, binarized models reach lower classification accuracies. To solve the problem of the trade-off between energy-efficiency and classification accuracy, we propose the QubitHD algorithm. It stochastically binarizes HD-based algorithms, while maintaining comparable classification accuracies to their non-binarized counterparts. The FPGA implementation of QubitHD provides a 65% improvement in terms of energy-efficiency, and a 95% improvement in terms of the training time, as compared to state-of-the-art HD-based ML algorithms. It also outperforms state-of-the-art low-cost classifiers (like Binarized Neural Networks) in terms of speed and energy-efficiency by an order of magnitude during training and inference.
Developing Synthesis Flows Without Human Knowledge
Apr 23, 2018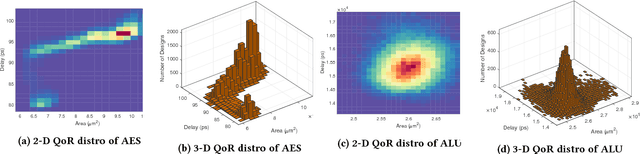

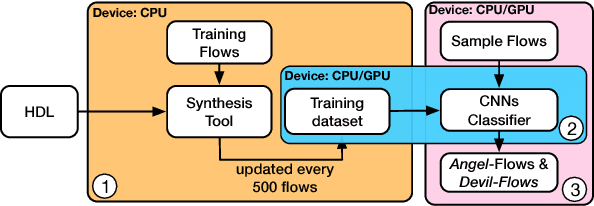
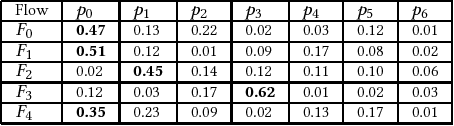
Design flows are the explicit combinations of design transformations, primarily involved in synthesis, placement and routing processes, to accomplish the design of Integrated Circuits (ICs) and System-on-Chip (SoC). Mostly, the flows are developed based on the knowledge of the experts. However, due to the large search space of design flows and the increasing design complexity, developing Intellectual Property (IP)-specific synthesis flows providing high Quality of Result (QoR) is extremely challenging. This work presents a fully autonomous framework that artificially produces design-specific synthesis flows without human guidance and baseline flows, using Convolutional Neural Network (CNN). The demonstrations are made by successfully designing logic synthesis flows of three large scaled designs.