 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Powers Product Retrieval for Long-tail Knowledge-Intensive Queries in E-commerce Search
Feb 27, 2026Product retrieval is the backbone of e-commerce search: for each user query, it identifies a high-recall candidate set from billions of items, laying the foundation for high-quality ranking and user experience. Despite extensive optimization for mainstream queries, existing systems still struggle with long-tail queries, especially knowledge-intensive ones. These queries exhibit diverse linguistic patterns, often lack explicit purchase intent, and require domain-specific knowledge reasoning for accurate interpretation. They also suffer from a shortage of reliable behavioral logs, which makes such queries a persistent challenge for retrieval optimization. To address these issues, we propose an efficient data synthesis framework tailored to retrieval involving long-tail, knowledge-intensive queries. The key idea is to implicitly distill the capabilities of a powerful offline query-rewriting model into an efficient online retrieval system. Leveraging the strong language understanding of LLMs, we train a multi-candidate query rewriting model with multiple reward signals and capture its rewriting capability in well-curated query-product pairs through a powerful offline retrieval pipeline. This design mitigates distributional shift in rewritten queries, which might otherwise limit incremental recall or introduce irrelevant products. Experiments demonstrate that without any additional tricks, simply incorporating this synthetic data into retrieval model training leads to significant improvements. Online Side-By-Side (SBS) human evaluation results indicate a notable enhancement in user search experience.
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
HUMANLLM: Benchmarking and Reinforcing LLM Anthropomorphism via Human Cognitive Patterns
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning and generation, serving as the foundation for advanced persona simulation and Role-Playing Language Agents (RPLAs). However, achieving authentic alignment with human cognitive and behavioral patterns remains a critical challenge for these agents. We present HUMANLLM, a framework treating psychological patterns as interacting causal forces. We construct 244 patterns from ~12,000 academic papers and synthesize 11,359 scenarios where 2-5 patterns reinforce, conflict, or modulate each other, with multi-turn conversations expressing inner thoughts, actions, and dialogue. Our dual-level checklists evaluate both individual pattern fidelity and emergent multi-pattern dynamics, achieving strong human alignment (r=0.91) while revealing that holistic metrics conflate simulation accuracy with social desirability. HUMANLLM-8B outperforms Qwen3-32B on multi-pattern dynamics despite 4x fewer parameters, demonstrating that authentic anthropomorphism requires cognitive modeling--simulating not just what humans do, but the psychological processes generating those behaviors.
Curse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
SmartRAG: Jointly Learn RAG-Related Tasks From the Environment Feedback
Oct 22, 2024



RAG systems consist of multiple modules to work together. However, these modules are usually separately trained. We argue that a system like RAG that incorporates multiple modules should be jointly optimized to achieve optimal performance. To demonstrate this, we design a specific pipeline called \textbf{SmartRAG} that includes a policy network and a retriever. The policy network can serve as 1) a decision maker that decides when to retrieve, 2) a query rewriter to generate a query most suited to the retriever, and 3) an answer generator that produces the final response with/without the observations. We then propose to jointly optimize the whole system using a reinforcement learning algorithm, with the reward designed to encourage the system to achieve the best performance with minimal retrieval cost. When jointly optimized, all the modules can be aware of how other modules are working and thus find the best way to work together as a complete system. Empirical results demonstrate that the jointly optimized SmartRAG can achieve better performance than separately optimized counterparts.
Controlling Character Motions without Observable Driving Source
Aug 11, 2023



How to generate diverse, life-like, and unlimited long head/body sequences without any driving source? We argue that this under-investigated research problem is non-trivial at all, and has unique technical challenges behind it. Without semantic constraints from the driving sources, using the standard autoregressive model to generate infinitely long sequences would easily result in 1) out-of-distribution (OOD) issue due to the accumulated error, 2) insufficient diversity to produce natural and life-like motion sequences and 3) undesired periodic patterns along the time. To tackle the above challenges, we propose a systematic framework that marries the benefits of VQ-VAE and a novel token-level control policy trained with reinforcement learning using carefully designed reward functions. A high-level prior model can be easily injected on top to generate unlimited long and diverse sequences. Although we focus on no driving sources now, our framework can be generalized for controlled synthesis with explicit driving sources. Through comprehensive evaluations, we conclude that our proposed framework can address all the above-mentioned challenges and outperform other strong baselines very significantly.
Deep Image Harmonization via Domain Verification
Nov 27, 2019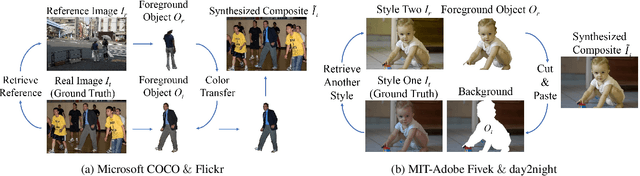
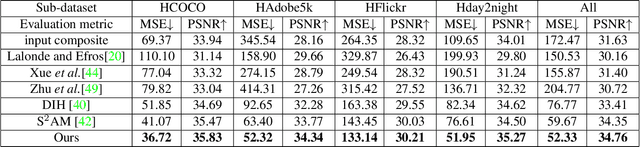
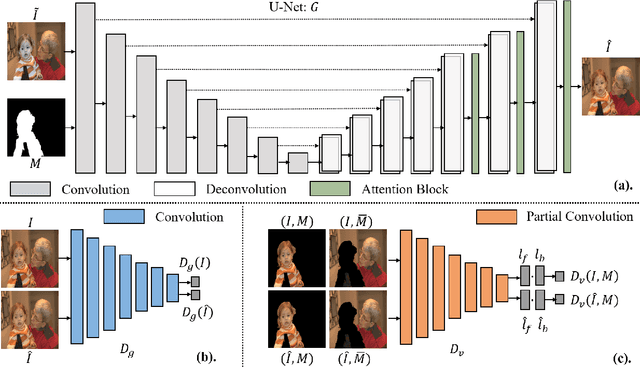

Image composition is an important operation in image processing, but the inconsistency between foreground and background significantly degrades the quality of composite image. Image harmonization, aiming to make the foreground compatible with the background, is a promising yet challenging task. However, the lack of high-quality publicly available dataset for image harmonization greatly hinders the development of image harmonization techniques. In this work, we contribute an image harmonization dataset by generating synthesized composite images based on COCO (resp., Adobe5k, Flickr, day2night) dataset, leading to our HCOCO (resp., HAdobe5k, HFlickr, Hday2night) sub-dataset. Moreover, we propose a new deep image harmonization method with a novel domain verification discriminator, enlightened by the following insight. Specifically, incompatible foreground and background belong to two different domains, so we need to translate the domain of foreground to the same domain as background. Our proposed domain verification discriminator can play such a role by pulling close the domains of foreground and background. Extensive experiments on our constructed dataset demonstrate the effectiveness of our proposed method. Our dataset is released in https://github.com/bcmi/Image_Harmonization_Datasets.
Image Harmonization Datasets: HCOCO, HAdobe5k, HFlickr, and Hday2night
Aug 28, 2019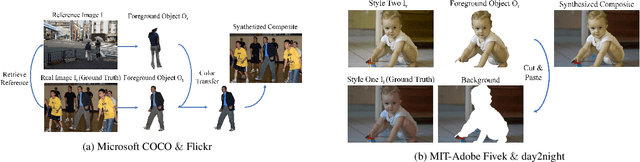
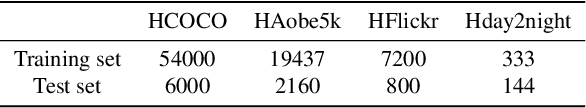
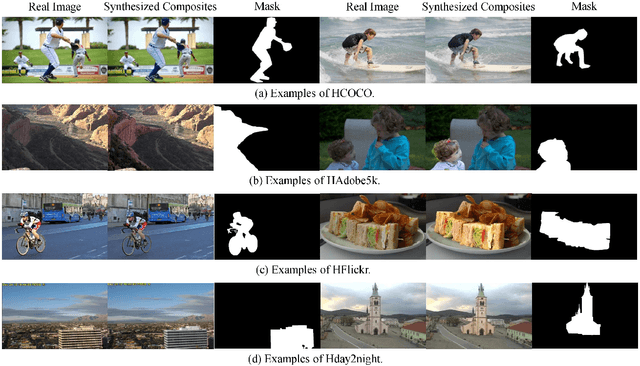
Image composition is an important operation in image processing, but the inconsistency between foreground and background significantly degrades the quality of composite image. Image harmonization, which aims to make the foreground compatible with the background, is a promising yet challenging task. However, the lack of high-quality public dataset for image harmonization, which significantly hinders the development of image harmonization techniques. Therefore, we create synthesized composite images based on existing COCO (resp., Adobe5k, day2night) dataset, leading to our HCOCO (resp., HAdobe5k, Hday2night) dataset. To enrich the diversity of our datasets, we also generate synthesized composite images based on our collected Flick images, leading to our HFlickr dataset. All four datasets are released in https://github.com/bcmi/Image_Harmonization_Datasets.