 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogiformer: A Two-Branch Graph Transformer Network for Interpretable Logical Reasoning
May 02, 2022

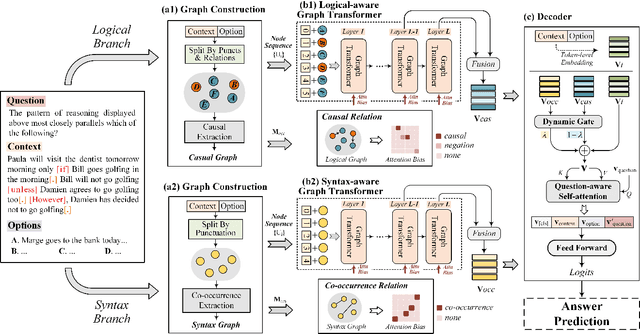
Machine reading comprehension has aroused wide concerns, since it explores the potential of model for text understanding. To further equip the machine with the reasoning capability, the challenging task of logical reasoning is proposed. Previous works on logical reasoning have proposed some strategies to extract the logical units from different aspects. However, there still remains a challenge to model the long distance dependency among the logical units. Also, it is demanding to uncover the logical structures of the text and further fuse the discrete logic to the continuous text embedding. To tackle the above issues, we propose an end-to-end model Logiformer which utilizes a two-branch graph transformer network for logical reasoning of text. Firstly, we introduce different extraction strategies to split the text into two sets of logical units, and construct the logical graph and the syntax graph respectively. The logical graph models the causal relations for the logical branch while the syntax graph captures the co-occurrence relations for the syntax branch. Secondly, to model the long distance dependency, the node sequence from each graph is fed into the fully connected graph transformer structures. The two adjacent matrices are viewed as the attention biases for the graph transformer layers, which map the discrete logical structures to the continuous text embedding space. Thirdly, a dynamic gate mechanism and a question-aware self-attention module are introduced before the answer prediction to update the features. The reasoning process provides the interpretability by employing the logical units, which are consistent with human cognition. The experimental results show the superiority of our model, which outperforms the state-of-the-art single model on two logical reasoning benchmarks.
MoCA: Incorporating Multi-stage Domain Pretraining and Cross-guided Multimodal Attention for Textbook Question Answering
Dec 06, 2021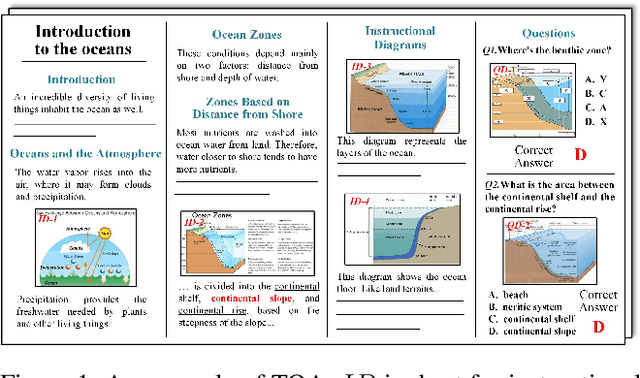

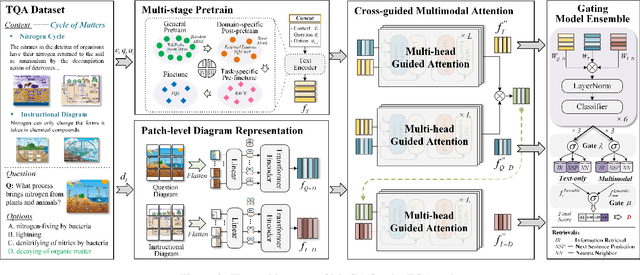
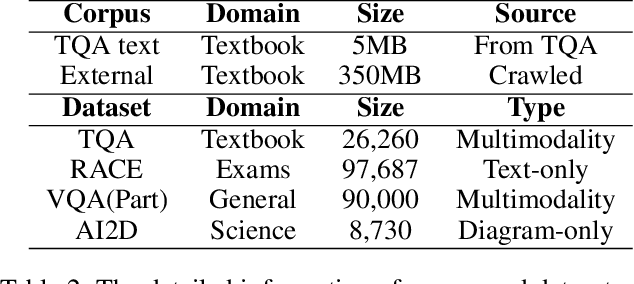
Textbook Question Answering (TQA) is a complex multimodal task to infer answers given large context descriptions and abundant diagrams. Compared with Visual Question Answering (VQA), TQA contains a large number of uncommon terminologies and various diagram inputs. It brings new challenges to the representation capability of language model for domain-specific spans. And it also pushes the multimodal fusion to a more complex level. To tackle the above issues, we propose a novel model named MoCA, which incorporates multi-stage domain pretraining and multimodal cross attention for the TQA task. Firstly, we introduce a multi-stage domain pretraining module to conduct unsupervised post-pretraining with the span mask strategy and supervised pre-finetune. Especially for domain post-pretraining, we propose a heuristic generation algorithm to employ the terminology corpus. Secondly, to fully consider the rich inputs of context and diagrams, we propose cross-guided multimodal attention to update the features of text, question diagram and instructional diagram based on a progressive strategy. Further, a dual gating mechanism is adopted to improve the model ensemble. The experimental results show the superiority of our model, which outperforms the state-of-the-art methods by 2.21% and 2.43% for validation and test split respectively.
Learning First-Order Rules with Relational Path Contrast for Inductive Relation Reasoning
Oct 17, 2021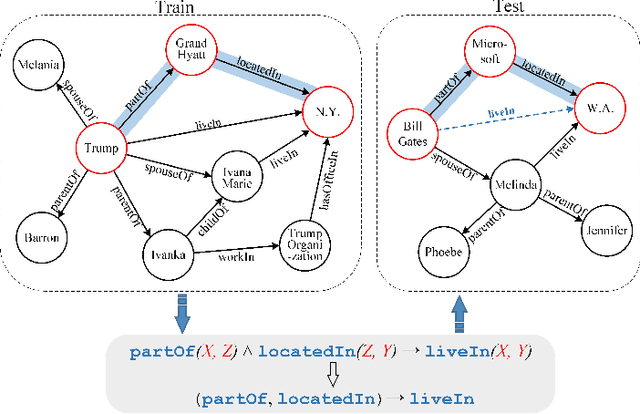
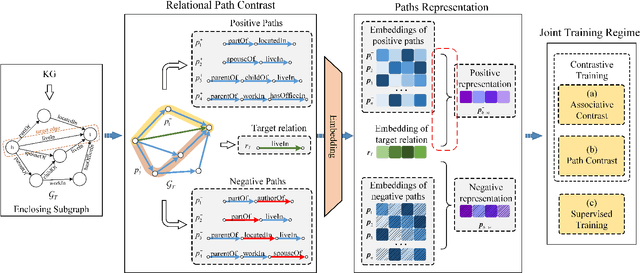
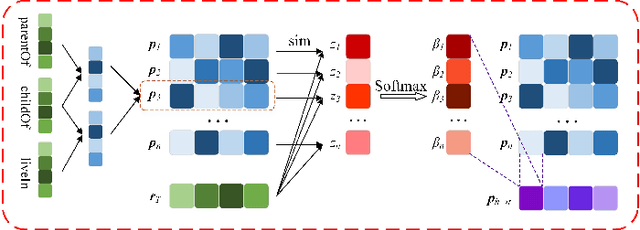
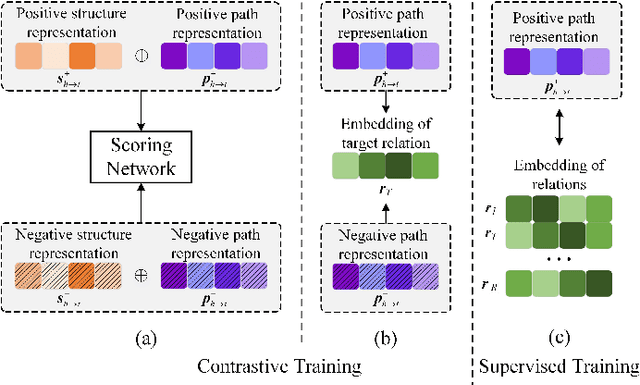
Relation reasoning in knowledge graphs (KGs) aims at predicting missing relations in incomplete triples, whereas the dominant paradigm is learning the embeddings of relations and entities, which is limited to a transductive setting and has restriction on processing unseen entities in an inductive situation. Previous inductive methods are scalable and consume less resource. They utilize the structure of entities and triples in subgraphs to own inductive ability. However, in order to obtain better reasoning results, the model should acquire entity-independent relational semantics in latent rules and solve the deficient supervision caused by scarcity of rules in subgraphs. To address these issues, we propose a novel graph convolutional network (GCN)-based approach for interpretable inductive reasoning with relational path contrast, named RPC-IR. RPC-IR firstly extracts relational paths between two entities and learns representations of them, and then innovatively introduces a contrastive strategy by constructing positive and negative relational paths. A joint training strategy considering both supervised and contrastive information is also proposed. Comprehensive experiments on three inductive datasets show that RPC-IR achieves outstanding performance comparing with the latest inductive reasoning methods and could explicitly represent logical rules for interpretability.