 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep evidential fusion with uncertainty quantification and contextual discounting for multimodal medical image segmentation
Paper and Code
Sep 12, 2023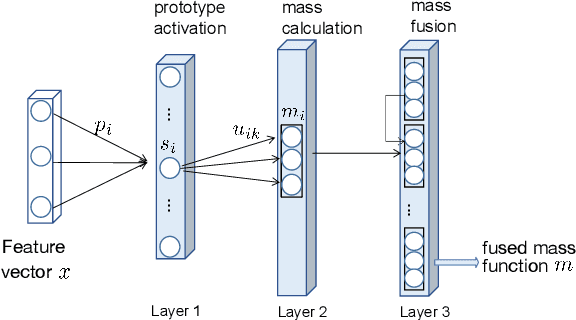
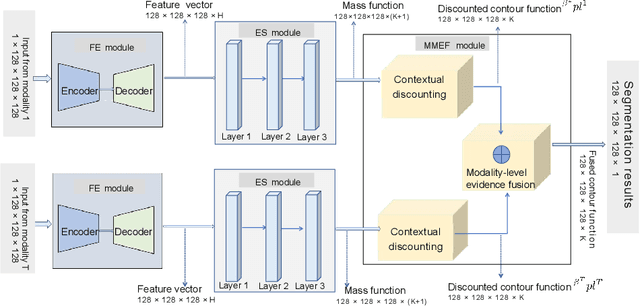
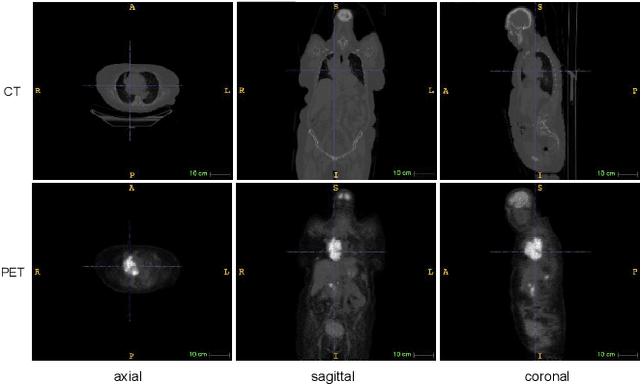
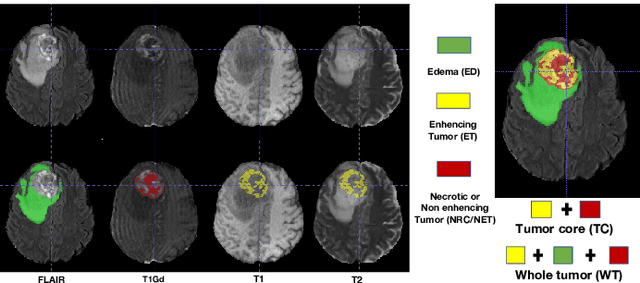
Single-modality medical images generally do not contain enough information to reach an accurate and reliable diagnosis. For this reason, physicians generally diagnose diseases based on multimodal medical images such as, e.g., PET/CT. The effective fusion of multimodal information is essential to reach a reliable decision and explain how the decision is made as well. In this paper, we propose a fusion framework for multimodal medical image segmentation based on deep learning and the Dempster-Shafer theory of evidence. In this framework, the reliability of each single modality image when segmenting different objects is taken into account by a contextual discounting operation. The discounted pieces of evidence from each modality are then combined by Dempster's rule to reach a final decision. Experimental results with a PET-CT dataset with lymphomas and a multi-MRI dataset with brain tumors show that our method outperforms the state-of-the-art methods in accuracy and reliability.