 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUINav: A maker of UI automation agents
Dec 15, 2023



An automation system that can execute natural language instructions by driving the user interface (UI) of an application can benefit users, especially when situationally or permanently impaired. Traditional automation systems (manual scripting, programming by demonstration tools, etc.) do not produce generalizable models that can tolerate changes in the UI or task workflow. Machine-learned automation agents generalize better, but either work only in simple, hand-crafted applications or rely on large pre-trained models, which may be too computationally expensive to run on mobile devices. In this paper, we propose \emph{UINav}, a demonstration-based agent maker system. UINav agents are lightweight enough to run on mobile devices, yet they achieve high success rates with a modest number of task demonstrations. To minimize the number of task demonstrations, UINav includes a referee model that allows users to receive immediate feedback on tasks where the agent is failing to best guide efforts to collect additional demonstrations. Further, UINav adopts macro actions to reduce an agent's state space, and augments human demonstrations to increase the diversity of training data. Our evaluation demonstrates that with an average of 10 demonstrations per task UINav can achieve an accuracy of 70\% or higher, and that with enough demonstrations it can achieve near-perfect success rates on 40+ different tasks.
SpreadsheetCoder: Formula Prediction from Semi-structured Context
Jun 26, 2021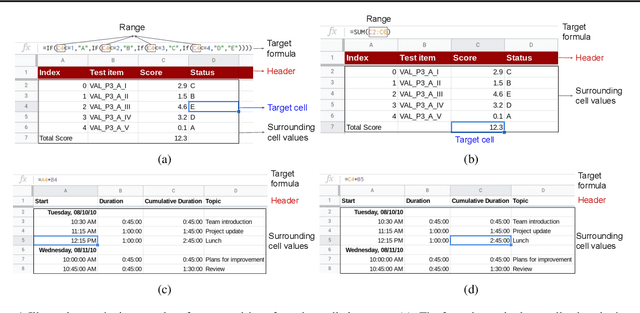
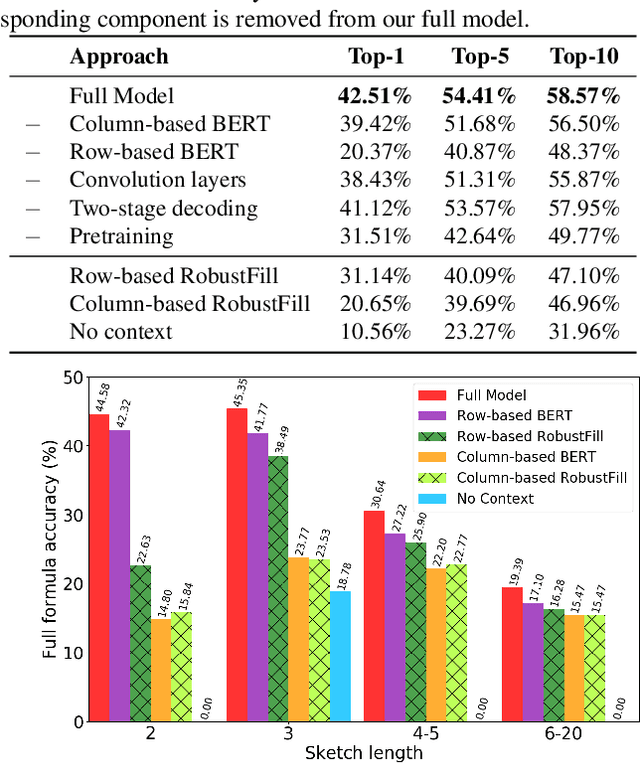

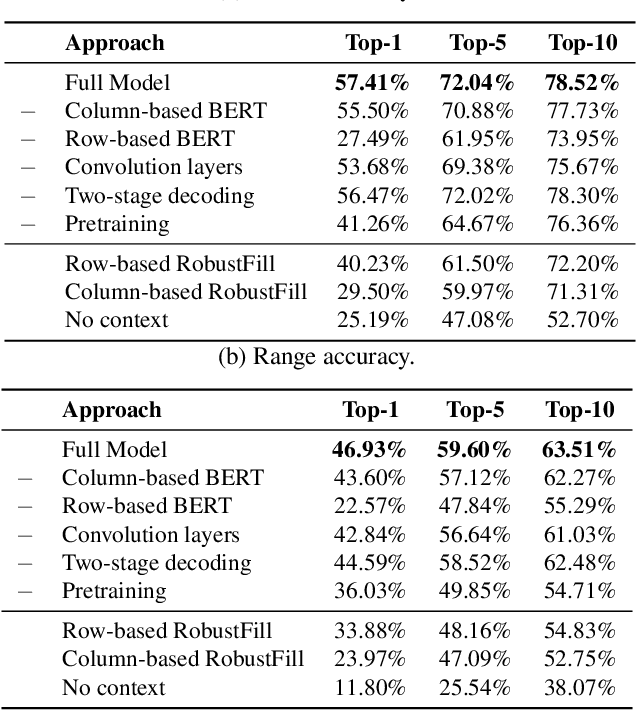
Spreadsheet formula prediction has been an important program synthesis problem with many real-world applications. Previous works typically utilize input-output examples as the specification for spreadsheet formula synthesis, where each input-output pair simulates a separate row in the spreadsheet. However, this formulation does not fully capture the rich context in real-world spreadsheets. First, spreadsheet data entries are organized as tables, thus rows and columns are not necessarily independent from each other. In addition, many spreadsheet tables include headers, which provide high-level descriptions of the cell data. However, previous synthesis approaches do not consider headers as part of the specification. In this work, we present the first approach for synthesizing spreadsheet formulas from tabular context, which includes both headers and semi-structured tabular data. In particular, we propose SpreadsheetCoder, a BERT-based model architecture to represent the tabular context in both row-based and column-based formats. We train our model on a large dataset of spreadsheets, and demonstrate that SpreadsheetCoder achieves top-1 prediction accuracy of 42.51%, which is a considerable improvement over baselines that do not employ rich tabular context. Compared to the rule-based system, SpreadsheetCoder assists 82% more users in composing formulas on Google Sheets.