 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Data Scale on Computer Control Agents
Jun 06, 2024
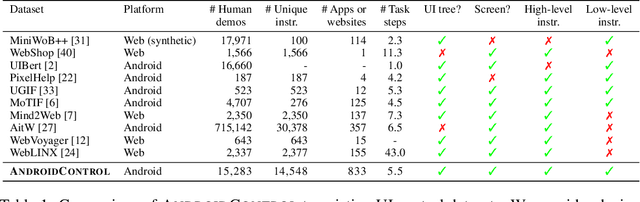
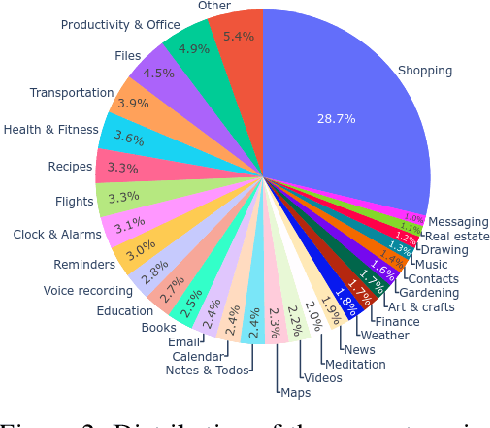

Autonomous agents that control computer interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world computer control agents. %In particularly, we investigate how performance measured on both high and low-level tasks in domain and out of domain scales as more training data is collected. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 15,283 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be insufficient for achieving robust out-of-domain performance.
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
May 23, 2024



Autonomous agents that execute human tasks by controlling computers can enhance human productivity and application accessibility. Yet, progress in this field will be driven by realistic and reproducible benchmarks. We present AndroidWorld, a fully functioning Android environment that provides reward signals for 116 programmatic task workflows across 20 real world Android applications. Unlike existing interactive environments, which provide a static test set, AndroidWorld dynamically constructs tasks that are parameterized and expressed in natural language in unlimited ways, thus enabling testing on a much larger and realistic suite of tasks. Reward signals are derived from the computer's system state, making them durable across task variations and extensible across different apps. To demonstrate AndroidWorld's benefits and mode of operation, we introduce a new computer control agent, M3A. M3A can complete 30.6% of the AndroidWorld's tasks, leaving ample room for future work. Furthermore, we adapt a popular desktop web agent to work on Android, which we find to be less effective on mobile, suggesting future research is needed to achieve universal, cross-domain agents. Finally, we conduct a robustness analysis by testing M3A against a range of task variations on a representative subset of tasks, demonstrating that variations in task parameters can significantly alter the complexity of a task and therefore an agent's performance, highlighting the importance of testing agents under diverse conditions. AndroidWorld and the experiments in this paper are available at https://github.com/google-research/android_world.
UINav: A maker of UI automation agents
Dec 15, 2023



An automation system that can execute natural language instructions by driving the user interface (UI) of an application can benefit users, especially when situationally or permanently impaired. Traditional automation systems (manual scripting, programming by demonstration tools, etc.) do not produce generalizable models that can tolerate changes in the UI or task workflow. Machine-learned automation agents generalize better, but either work only in simple, hand-crafted applications or rely on large pre-trained models, which may be too computationally expensive to run on mobile devices. In this paper, we propose \emph{UINav}, a demonstration-based agent maker system. UINav agents are lightweight enough to run on mobile devices, yet they achieve high success rates with a modest number of task demonstrations. To minimize the number of task demonstrations, UINav includes a referee model that allows users to receive immediate feedback on tasks where the agent is failing to best guide efforts to collect additional demonstrations. Further, UINav adopts macro actions to reduce an agent's state space, and augments human demonstrations to increase the diversity of training data. Our evaluation demonstrates that with an average of 10 demonstrations per task UINav can achieve an accuracy of 70\% or higher, and that with enough demonstrations it can achieve near-perfect success rates on 40+ different tasks.