 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the challenges of learning with inference networks on sparse, high-dimensional data
Paper and Code

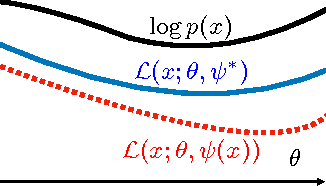
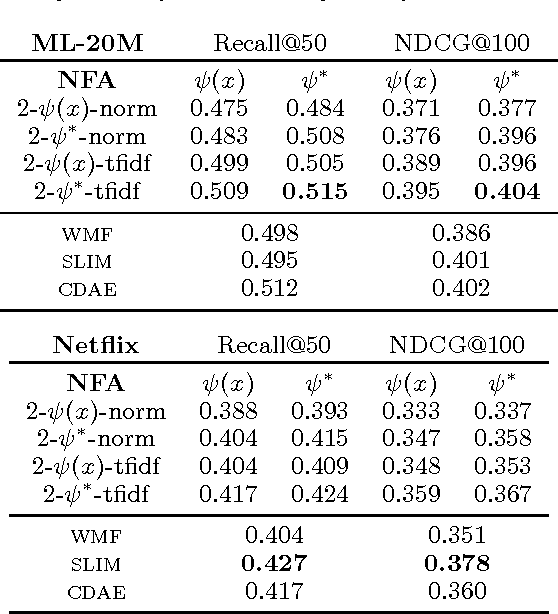
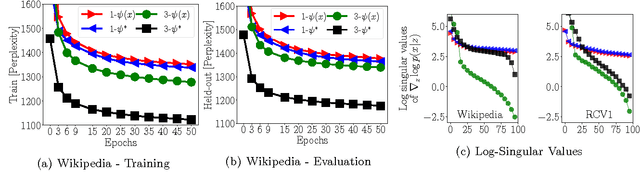
We study parameter estimation in Nonlinear Factor Analysis (NFA) where the generative model is parameterized by a deep neural network. Recent work has focused on learning such models using inference (or recognition) networks; we identify a crucial problem when modeling large, sparse, high-dimensional datasets -- underfitting. We study the extent of underfitting, highlighting that its severity increases with the sparsity of the data. We propose methods to tackle it via iterative optimization inspired by stochastic variational inference \citep{hoffman2013stochastic} and improvements in the sparse data representation used for inference. The proposed techniques drastically improve the ability of these powerful models to fit sparse data, achieving state-of-the-art results on a benchmark text-count dataset and excellent results on the task of top-N recommendation.