Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Generation
Paper and Code
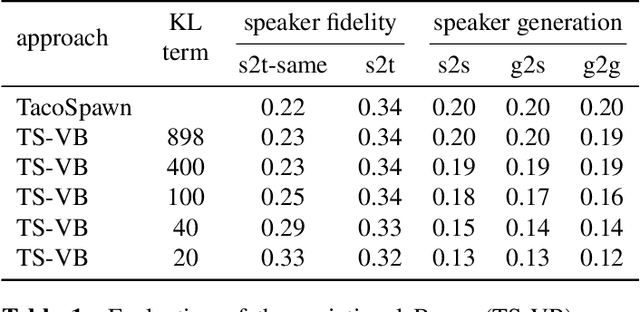
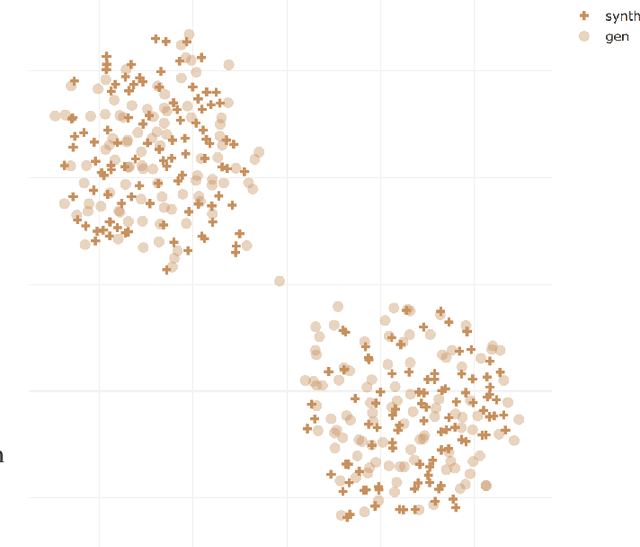
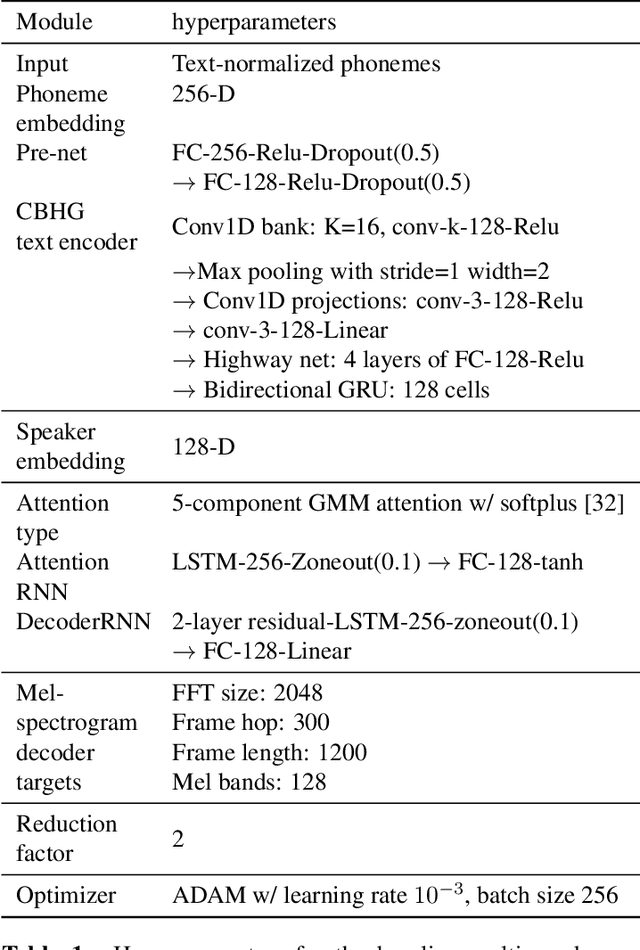
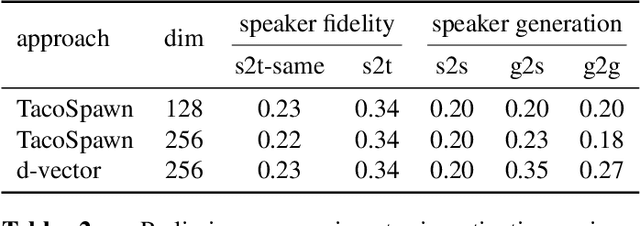
This work explores the task of synthesizing speech in nonexistent human-sounding voices. We call this task "speaker generation", and present TacoSpawn, a system that performs competitively at this task. TacoSpawn is a recurrent attention-based text-to-speech model that learns a distribution over a speaker embedding space, which enables sampling of novel and diverse speakers. Our method is easy to implement, and does not require transfer learning from speaker ID systems. We present objective and subjective metrics for evaluating performance on this task, and demonstrate that our proposed objective metrics correlate with human perception of speaker similarity. Audio samples are available on our demo page.
* 12 pages, 3 figures, 4 tables, appendix with 2 tables
View paper on